Overcoming Weak Visual-Textual Alignment for Video Moment Retrieval
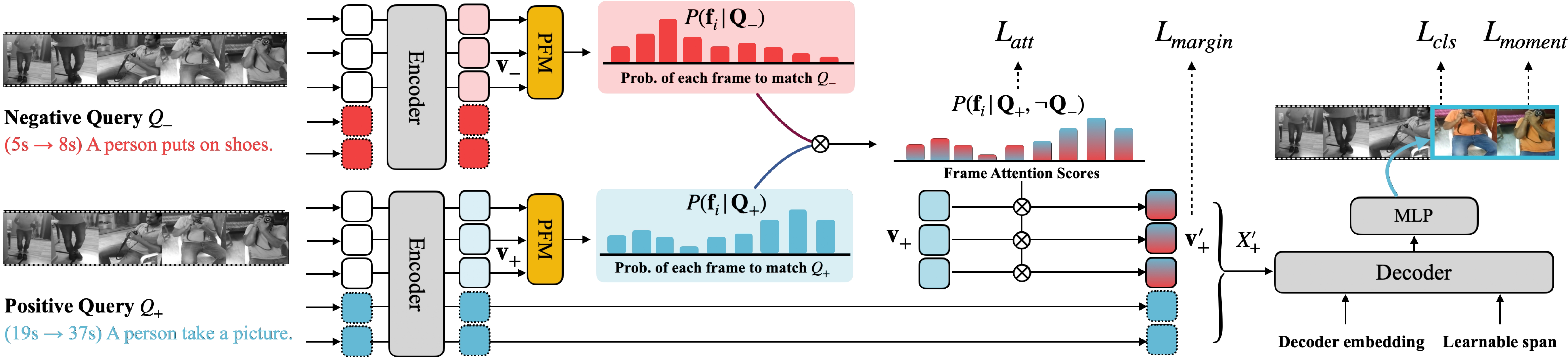
Video moment retrieval (VMR) identifies a specific moment in an untrimmed video for a given natural language query. This task is prone to suffer the weak visual-textual alignment problem innate in video datasets. Due to the ambiguity, a query does not fully cover the relevant details of the corresponding moment, or the moment may contain misaligned and irrelevant frames, potentially limiting further performance gains. To tackle this problem, we propose a background-aware moment detection transformer (BM-DETR). Our model adopts a contrastive approach, carefully utilizing the negative queries matched to other moments in the video. Specifically, our model learns to predict the target moment from the joint probability of each frame given the positive query and the complement of negative queries. This leads to effective use of the surrounding background, improving moment sensitivity and enhancing overall alignments in videos. Extensive experiments on four benchmarks demonstrate the effectiveness of our approach.
PDF Abstract


 ActivityNet Captions
ActivityNet Captions
 Charades-STA
Charades-STA
 QVHighlights
QVHighlights

