Optimistic Multi-Agent Policy Gradient for Cooperative Tasks
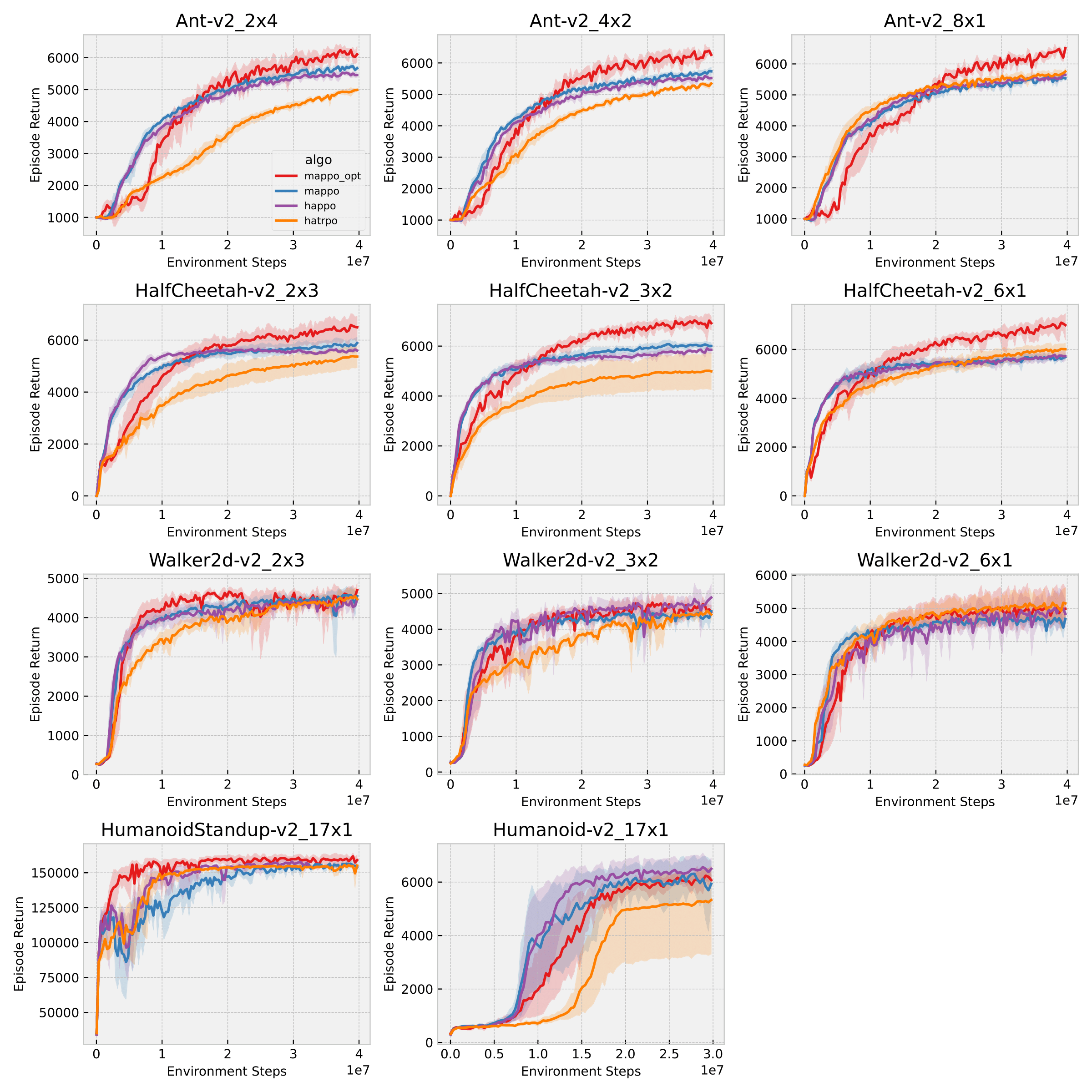
\textit{Relative overgeneralization} (RO) occurs in cooperative multi-agent learning tasks when agents converge towards a suboptimal joint policy due to overfitting to suboptimal behavior of other agents. In early work, optimism has been shown to mitigate the \textit{RO} problem when using tabular Q-learning. However, with function approximation optimism can amplify overestimation and thus fail on complex tasks. On the other hand, recent deep multi-agent policy gradient (MAPG) methods have succeeded in many complex tasks but may fail with severe \textit{RO}. We propose a general, yet simple, framework to enable optimistic updates in MAPG methods and alleviate the RO problem. Specifically, we employ a \textit{Leaky ReLU} function where a single hyperparameter selects the degree of optimism to reshape the advantages when updating the policy. Intuitively, our method remains optimistic toward individual actions with lower returns which are potentially caused by other agents' sub-optimal behavior during learning. The optimism prevents the individual agents from quickly converging to a local optimum. We also provide a formal analysis from an operator view to understand the proposed advantage transformation. In extensive evaluations on diverse sets of tasks, including illustrative matrix games, complex \textit{Multi-agent MuJoCo} and \textit{Overcooked} benchmarks, the proposed method\footnote{Code can be found at \url{https://github.com/wenshuaizhao/optimappo}.} outperforms strong baselines on 13 out of 19 tested tasks and matches the performance on the rest.
PDF Abstract

