OpenSR: Open-Modality Speech Recognition via Maintaining Multi-Modality Alignment
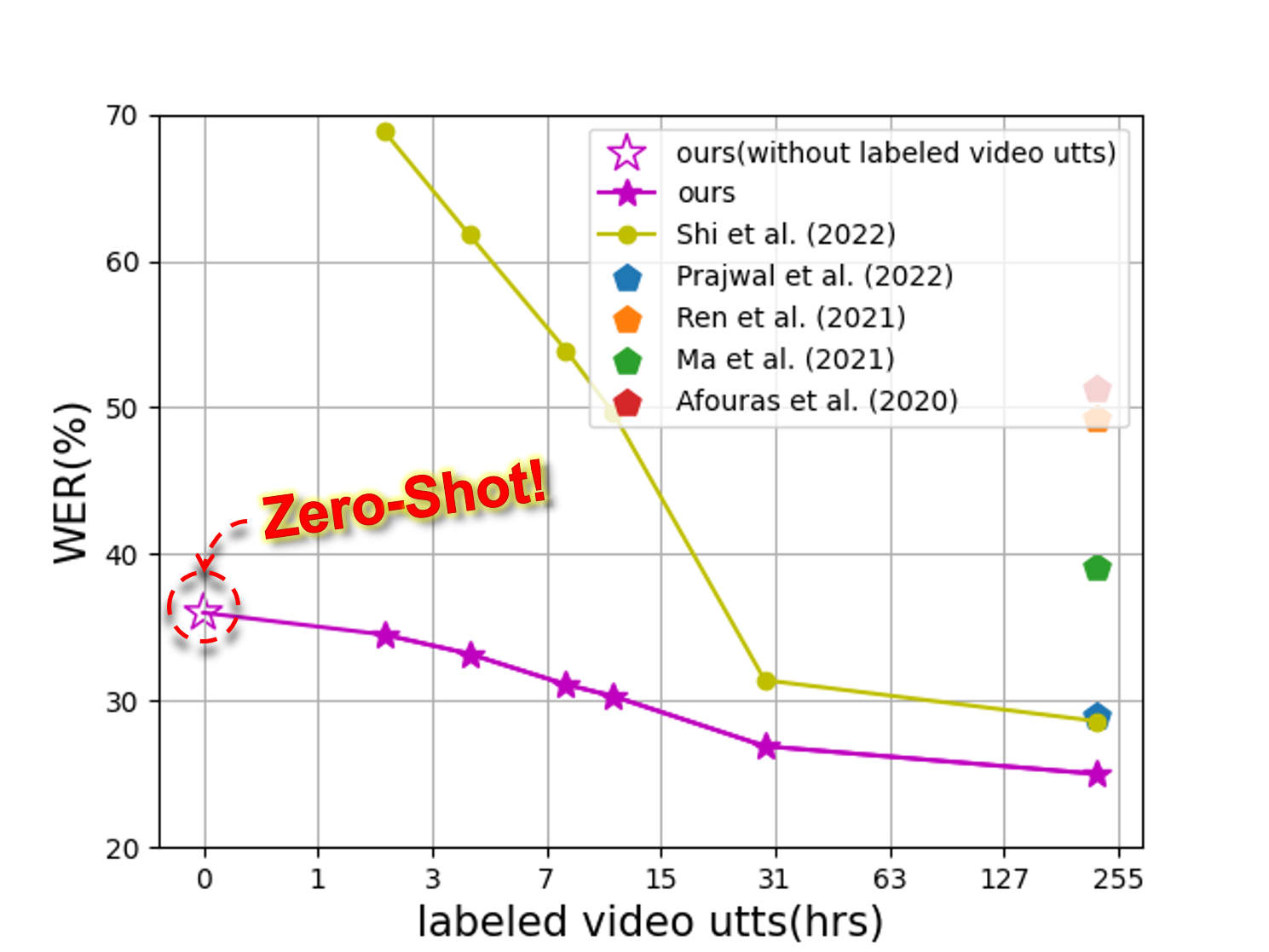
Speech Recognition builds a bridge between the multimedia streaming (audio-only, visual-only or audio-visual) and the corresponding text transcription. However, when training the specific model of new domain, it often gets stuck in the lack of new-domain utterances, especially the labeled visual utterances. To break through this restriction, we attempt to achieve zero-shot modality transfer by maintaining the multi-modality alignment in phoneme space learned with unlabeled multimedia utterances in the high resource domain during the pre-training \cite{shi2022learning}, and propose a training system Open-modality Speech Recognition (\textbf{OpenSR}) that enables the models trained on a single modality (e.g., audio-only) applicable to more modalities (e.g., visual-only and audio-visual). Furthermore, we employ a cluster-based prompt tuning strategy to handle the domain shift for the scenarios with only common words in the new domain utterances. We demonstrate that OpenSR enables modality transfer from one to any in three different settings (zero-, few- and full-shot), and achieves highly competitive zero-shot performance compared to the existing few-shot and full-shot lip-reading methods. To the best of our knowledge, OpenSR achieves the state-of-the-art performance of word error rate in LRS2 on audio-visual speech recognition and lip-reading with 2.7\% and 25.0\%, respectively. The code and demo are available at https://github.com/Exgc/OpenSR.
PDF Abstract


 LRS2
LRS2
