Open Scene Understanding: Grounded Situation Recognition Meets Segment Anything for Helping People with Visual Impairments
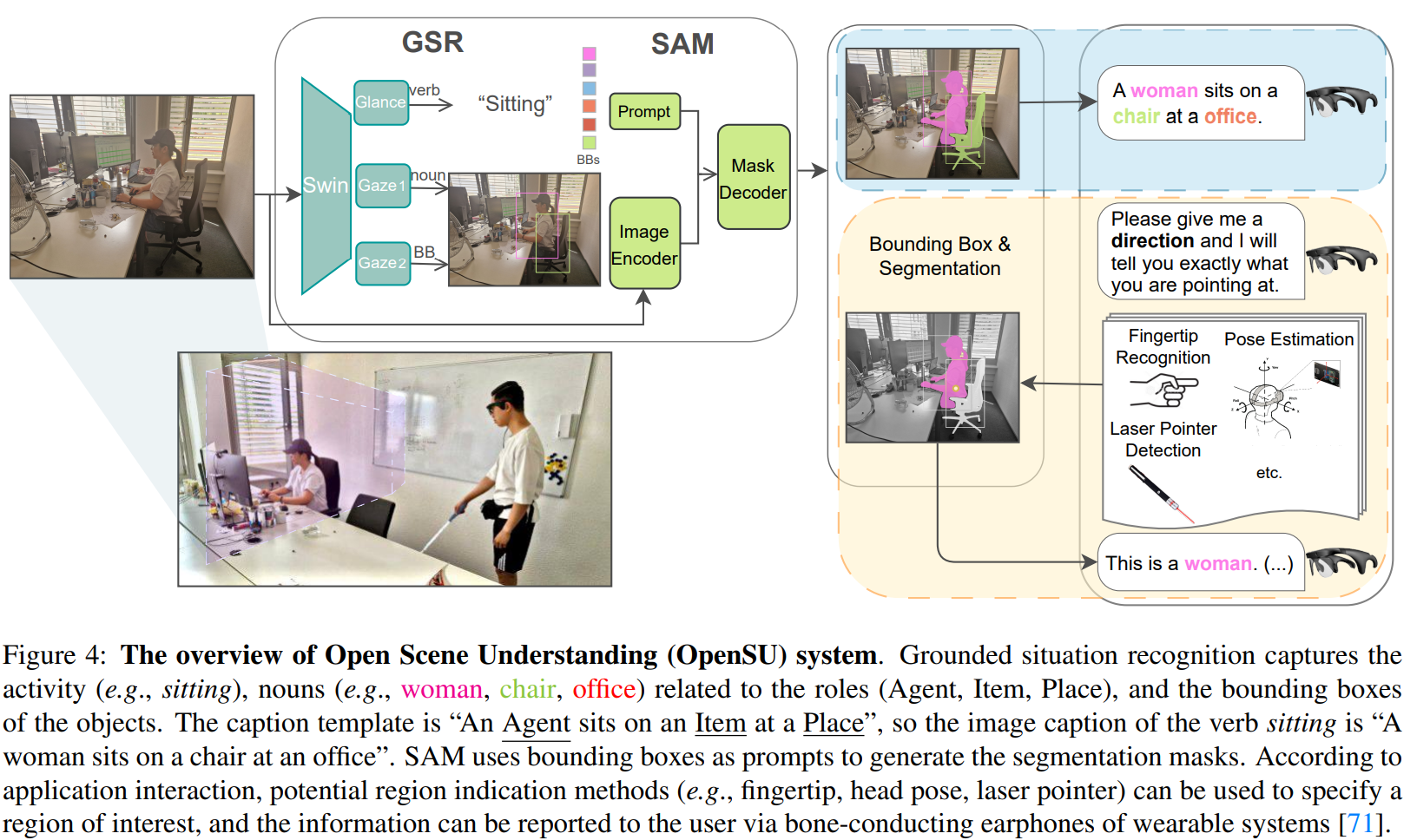
Grounded Situation Recognition (GSR) is capable of recognizing and interpreting visual scenes in a contextually intuitive way, yielding salient activities (verbs) and the involved entities (roles) depicted in images. In this work, we focus on the application of GSR in assisting people with visual impairments (PVI). However, precise localization information of detected objects is often required to navigate their surroundings confidently and make informed decisions. For the first time, we propose an Open Scene Understanding (OpenSU) system that aims to generate pixel-wise dense segmentation masks of involved entities instead of bounding boxes. Specifically, we build our OpenSU system on top of GSR by additionally adopting an efficient Segment Anything Model (SAM). Furthermore, to enhance the feature extraction and interaction between the encoder-decoder structure, we construct our OpenSU system using a solid pure transformer backbone to improve the performance of GSR. In order to accelerate the convergence, we replace all the activation functions within the GSR decoders with GELU, thereby reducing the training duration. In quantitative analysis, our model achieves state-of-the-art performance on the SWiG dataset. Moreover, through field testing on dedicated assistive technology datasets and application demonstrations, the proposed OpenSU system can be used to enhance scene understanding and facilitate the independent mobility of people with visual impairments. Our code will be available at https://github.com/RuipingL/OpenSU.
PDF Abstract

 ImageNet
ImageNet
 FrameNet
FrameNet
