Open Problems in Applied Deep Learning
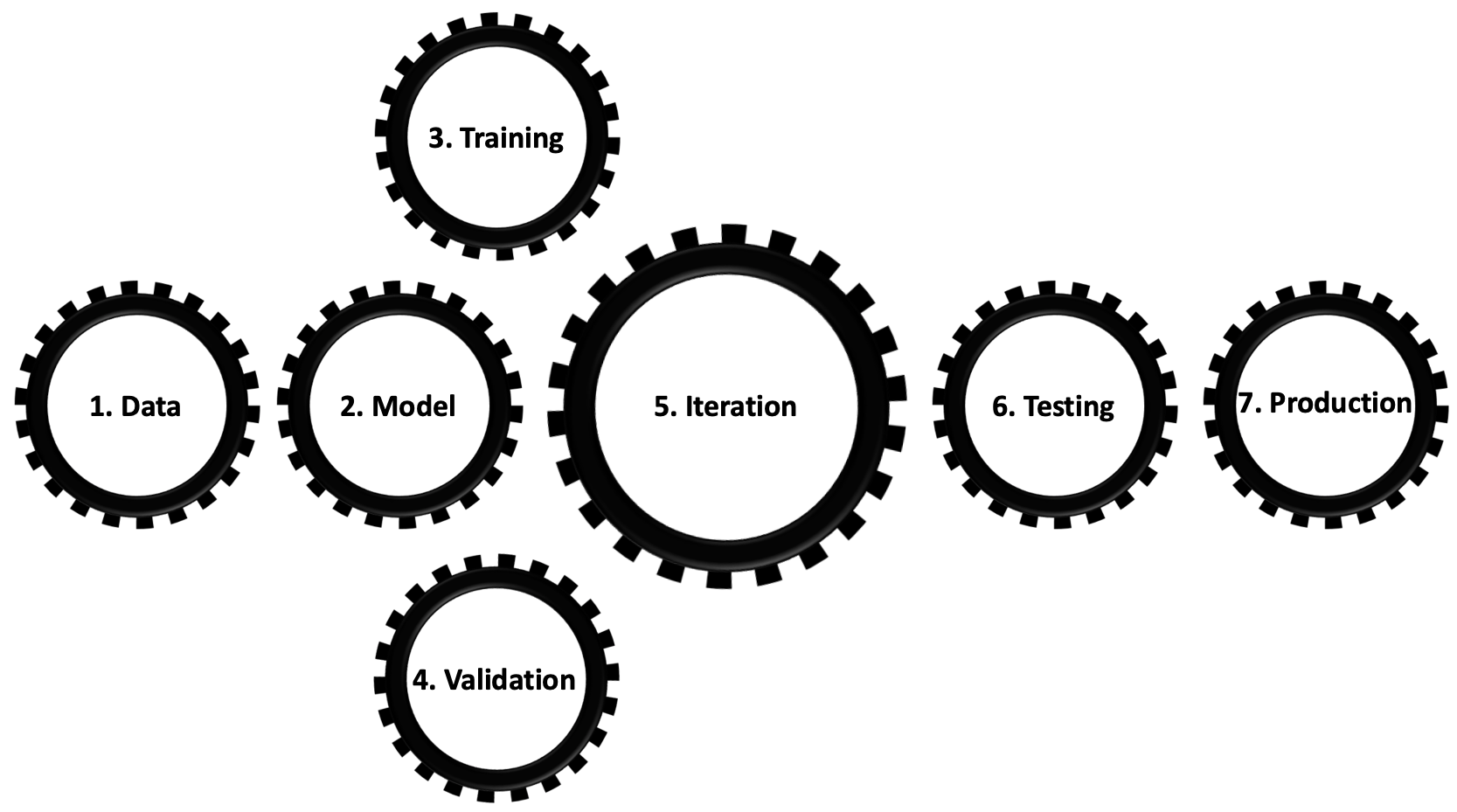
This work formulates the machine learning mechanism as a bi-level optimization problem. The inner level optimization loop entails minimizing a properly chosen loss function evaluated on the training data. This is nothing but the well-studied training process in pursuit of optimal model parameters. The outer level optimization loop is less well-studied and involves maximizing a properly chosen performance metric evaluated on the validation data. This is what we call the "iteration process", pursuing optimal model hyper-parameters. Among many other degrees of freedom, this process entails model engineering (e.g., neural network architecture design) and management, experiment tracking, dataset versioning and augmentation. The iteration process could be automated via Automatic Machine Learning (AutoML) or left to the intuitions of machine learning students, engineers, and researchers. Regardless of the route we take, there is a need to reduce the computational cost of the iteration step and as a direct consequence reduce the carbon footprint of developing artificial intelligence algorithms. Despite the clean and unified mathematical formulation of the iteration step as a bi-level optimization problem, its solutions are case specific and complex. This work will consider such cases while increasing the level of complexity from supervised learning to semi-supervised, self-supervised, unsupervised, few-shot, federated, reinforcement, and physics-informed learning. As a consequence of this exercise, this proposal surfaces a plethora of open problems in the field, many of which can be addressed in parallel.
PDF Abstract

