OOP: Object-Oriented Programming Evaluation Benchmark for Large Language Models
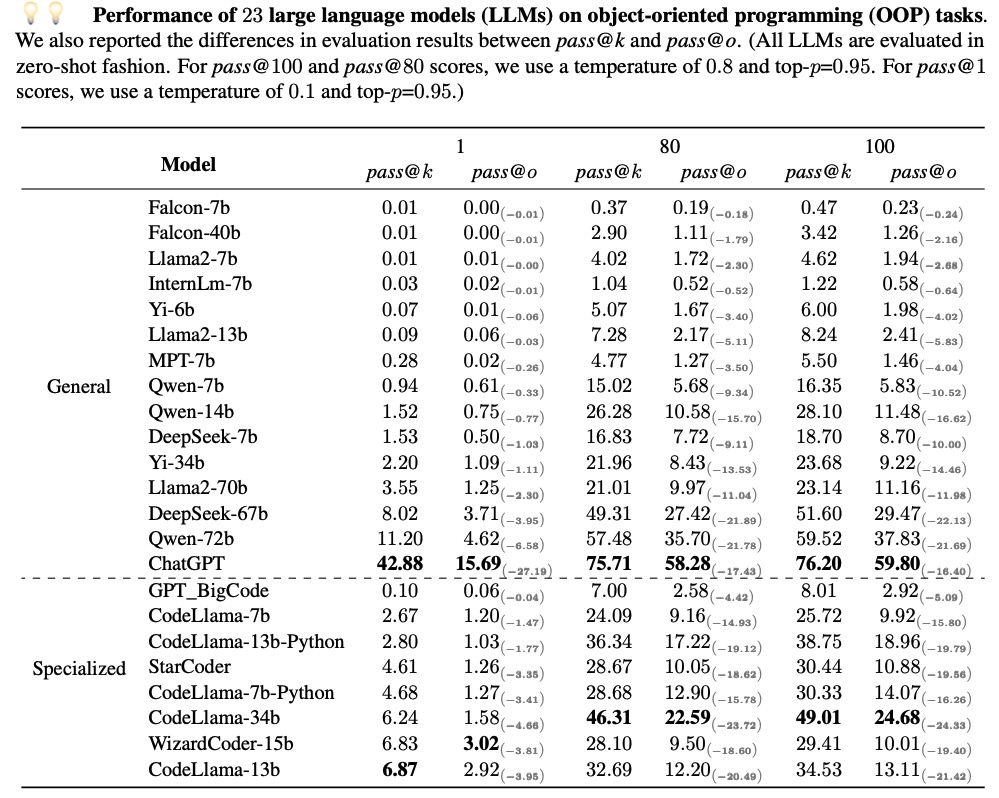
Advancing automated programming necessitates robust and comprehensive code generation benchmarks, yet current evaluation frameworks largely neglect object-oriented programming (OOP) in favor of functional programming (FP), e.g., HumanEval and MBPP. To address this, our study introduces a pioneering OOP-focused benchmark, featuring 431 Python programs that encompass essential OOP concepts and features like classes and encapsulation methods. We propose a novel evaluation metric, pass@o, tailored for OOP, enhancing traditional pass@k measures. Our evaluation of 23 leading large language models (LLMs), including both general and code-specialized models, reveals three key insights: 1) pass@o offers a more relevant and comprehensive assessment for OOP code generation; 2) Despite excelling in FP, code-specialized LLMs like WizardCoder lag in OOP compared to models like ChatGPT; 3) The poor performance of all advanced LLMs on our OOP benchmark highlights a critical need for improvements in this field. Our benchmark and scripts are publicly released at: https://github.com/alphadl/OOP-eval.
PDF Abstract
 HumanEval
HumanEval
