OnlineRefer: A Simple Online Baseline for Referring Video Object Segmentation
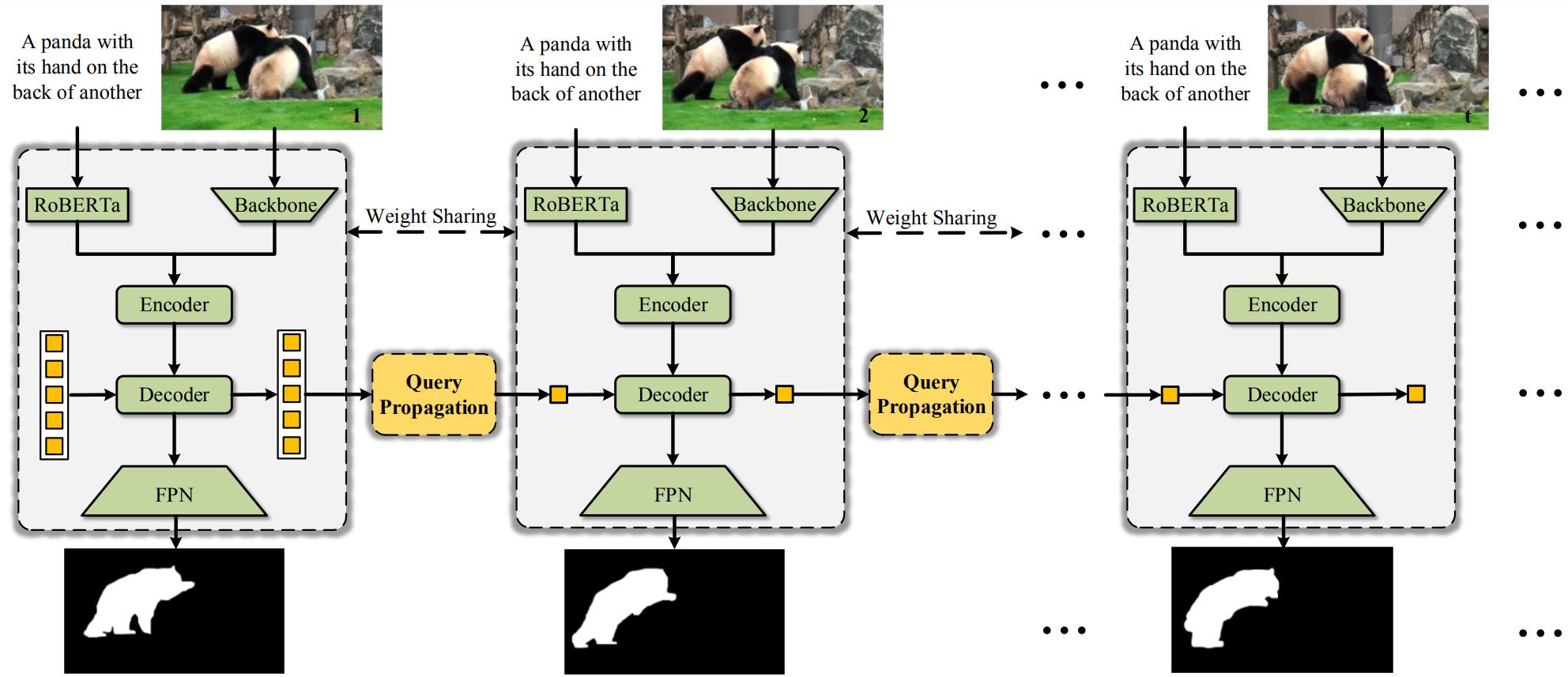
Referring video object segmentation (RVOS) aims at segmenting an object in a video following human instruction. Current state-of-the-art methods fall into an offline pattern, in which each clip independently interacts with text embedding for cross-modal understanding. They usually present that the offline pattern is necessary for RVOS, yet model limited temporal association within each clip. In this work, we break up the previous offline belief and propose a simple yet effective online model using explicit query propagation, named OnlineRefer. Specifically, our approach leverages target cues that gather semantic information and position prior to improve the accuracy and ease of referring predictions for the current frame. Furthermore, we generalize our online model into a semi-online framework to be compatible with video-based backbones. To show the effectiveness of our method, we evaluate it on four benchmarks, \ie, Refer-Youtube-VOS, Refer-DAVIS17, A2D-Sentences, and JHMDB-Sentences. Without bells and whistles, our OnlineRefer with a Swin-L backbone achieves 63.5 J&F and 64.8 J&F on Refer-Youtube-VOS and Refer-DAVIS17, outperforming all other offline methods.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract




 Refer-YouTube-VOS
Refer-YouTube-VOS

