One-step and Two-step Classification for Abusive Language Detection on Twitter
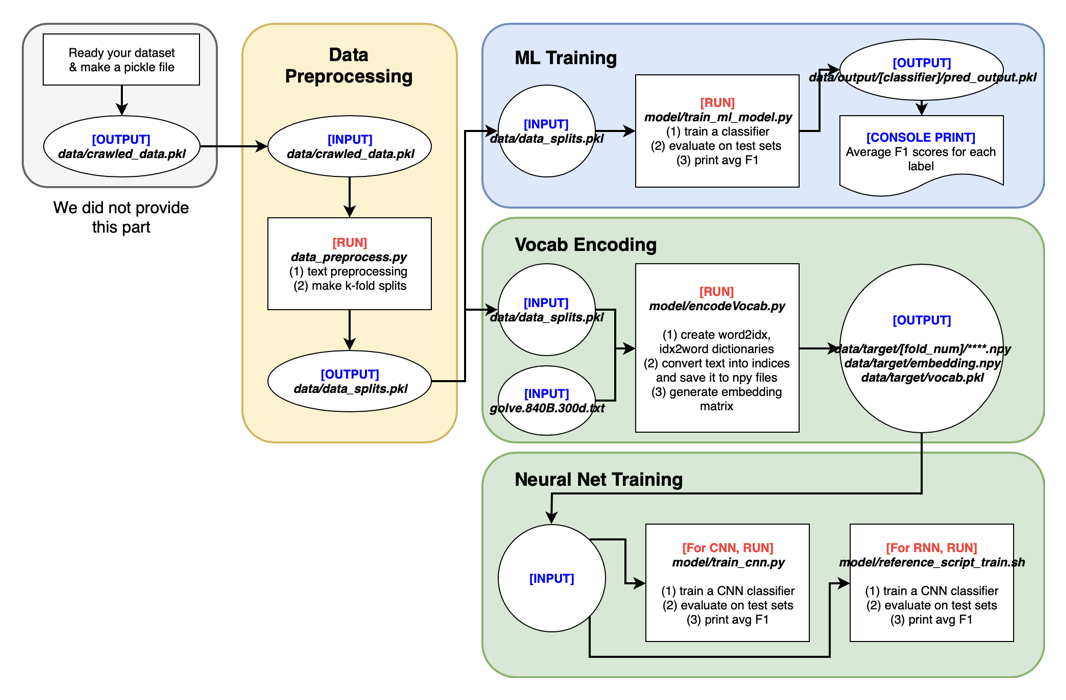
Automatic abusive language detection is a difficult but important task for online social media. Our research explores a two-step approach of performing classification on abusive language and then classifying into specific types and compares it with one-step approach of doing one multi-class classification for detecting sexist and racist languages. With a public English Twitter corpus of 20 thousand tweets in the type of sexism and racism, our approach shows a promising performance of 0.827 F-measure by using HybridCNN in one-step and 0.824 F-measure by using logistic regression in two-steps.
PDF Abstract WS 2017 PDF WS 2017 Abstract



Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
