One For All: Video Conversation is Feasible Without Video Instruction Tuning
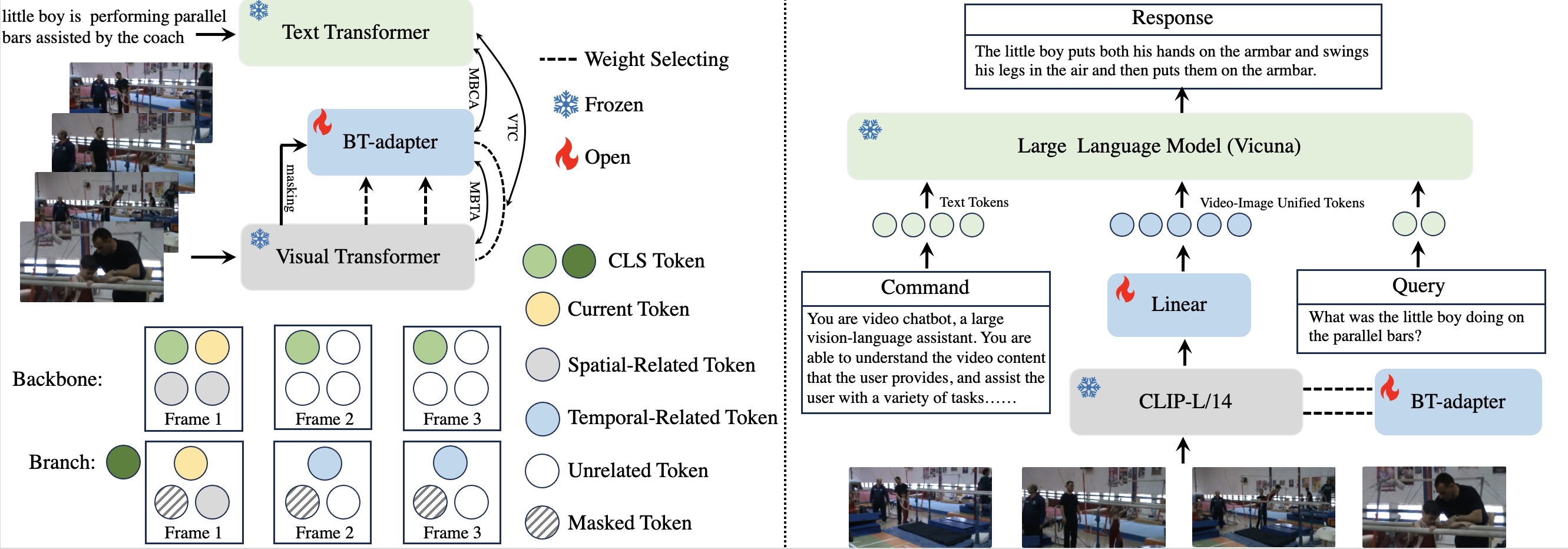
The recent progress in Large Language Models (LLM) has spurred various advancements in image-language conversation agents, while how to build a proficient video-based dialogue system is still under exploration. Considering the extensive scale of LLM and visual backbone, minimal GPU memory is left for facilitating effective temporal modeling, which is crucial for comprehending and providing feedback on videos. To this end, we propose Branching Temporal Adapter (BT-Adapter), a novel method for extending image-language pretrained models into the video domain. Specifically, BT-Adapter serves as a plug-and-use temporal modeling branch alongside the pretrained visual encoder, which is tuned while keeping the backbone frozen. Just pretrained once, BT-Adapter can be seamlessly integrated into all image conversation models using this version of CLIP, enabling video conversations without the need for video instructions. Besides, we develop a unique asymmetric token masking strategy inside the branch with tailor-made training tasks for BT-Adapter, facilitating faster convergence and better results. Thanks to BT-Adapter, we are able to empower existing multimodal dialogue models with strong video understanding capabilities without incurring excessive GPU costs. Without bells and whistles, BT-Adapter achieves (1) state-of-the-art zero-shot results on various video tasks using thousands of fewer GPU hours. (2) better performance than current video chatbots without any video instruction tuning. (3) state-of-the-art results of video chatting using video instruction tuning, outperforming previous SOTAs by a large margin.
PDF Abstract
Tasks
 Video-based Generative Performance Benchmarking
Video-based Generative Performance Benchmarking (Consistency)
Video-based Generative Performance Benchmarking (Contextual Understanding)
Video-based Generative Performance Benchmarking (Correctness of Information)
Video-based Generative Performance Benchmarking (Detail Orientation))
Video-based Generative Performance Benchmarking (Temporal Understanding)
Video Question Answering
Video Understanding
Zero-Shot Video Question Answer
Zero-Shot Video Retrieval
Video-based Generative Performance Benchmarking
Video-based Generative Performance Benchmarking (Consistency)
Video-based Generative Performance Benchmarking (Contextual Understanding)
Video-based Generative Performance Benchmarking (Correctness of Information)
Video-based Generative Performance Benchmarking (Detail Orientation))
Video-based Generative Performance Benchmarking (Temporal Understanding)
Video Question Answering
Video Understanding
Zero-Shot Video Question Answer
Zero-Shot Video Retrieval
 ActivityNet
ActivityNet
 MSR-VTT
MSR-VTT
 DiDeMo
DiDeMo
 WebVid
WebVid
 LSMDC
LSMDC
 ActivityNet-QA
ActivityNet-QA

