On the Expressivity Role of LayerNorm in Transformers' Attention
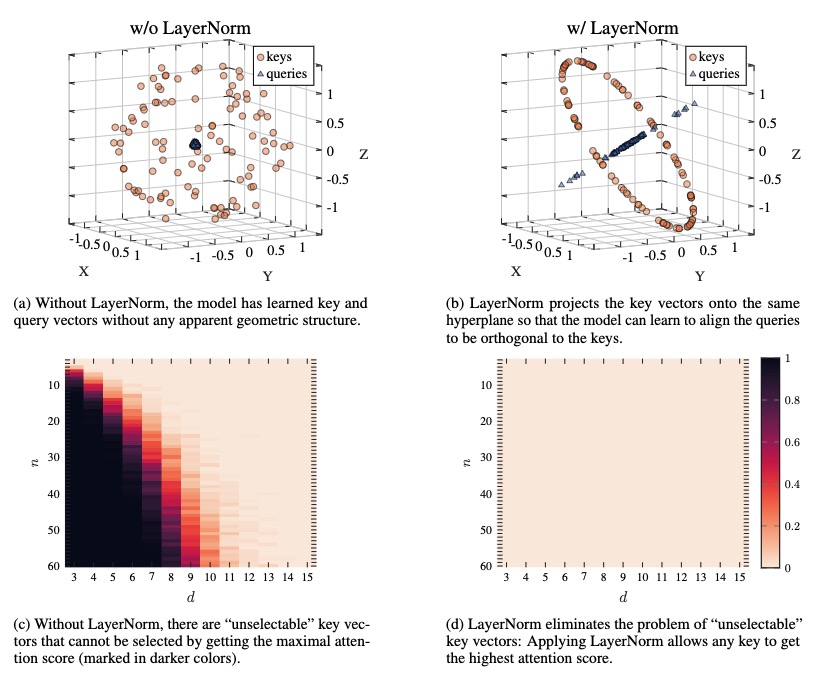
Layer Normalization (LayerNorm) is an inherent component in all Transformer-based models. In this paper, we show that LayerNorm is crucial to the expressivity of the multi-head attention layer that follows it. This is in contrast to the common belief that LayerNorm's only role is to normalize the activations during the forward pass, and their gradients during the backward pass. We consider a geometric interpretation of LayerNorm and show that it consists of two components: (a) projection of the input vectors to a $d-1$ space that is orthogonal to the $\left[1,1,...,1\right]$ vector, and (b) scaling of all vectors to the same norm of $\sqrt{d}$. We show that each of these components is important for the attention layer that follows it in Transformers: (a) projection allows the attention mechanism to create an attention query that attends to all keys equally, offloading the need to learn this operation by the attention; and (b) scaling allows each key to potentially receive the highest attention, and prevents keys from being "un-select-able". We show empirically that Transformers do indeed benefit from these properties of LayeNorm in general language modeling and even in computing simple functions such as "majority". Our code is available at https://github.com/tech-srl/layer_norm_expressivity_role .
PDF Abstract

