On Diversified Preferences of Large Language Model Alignment
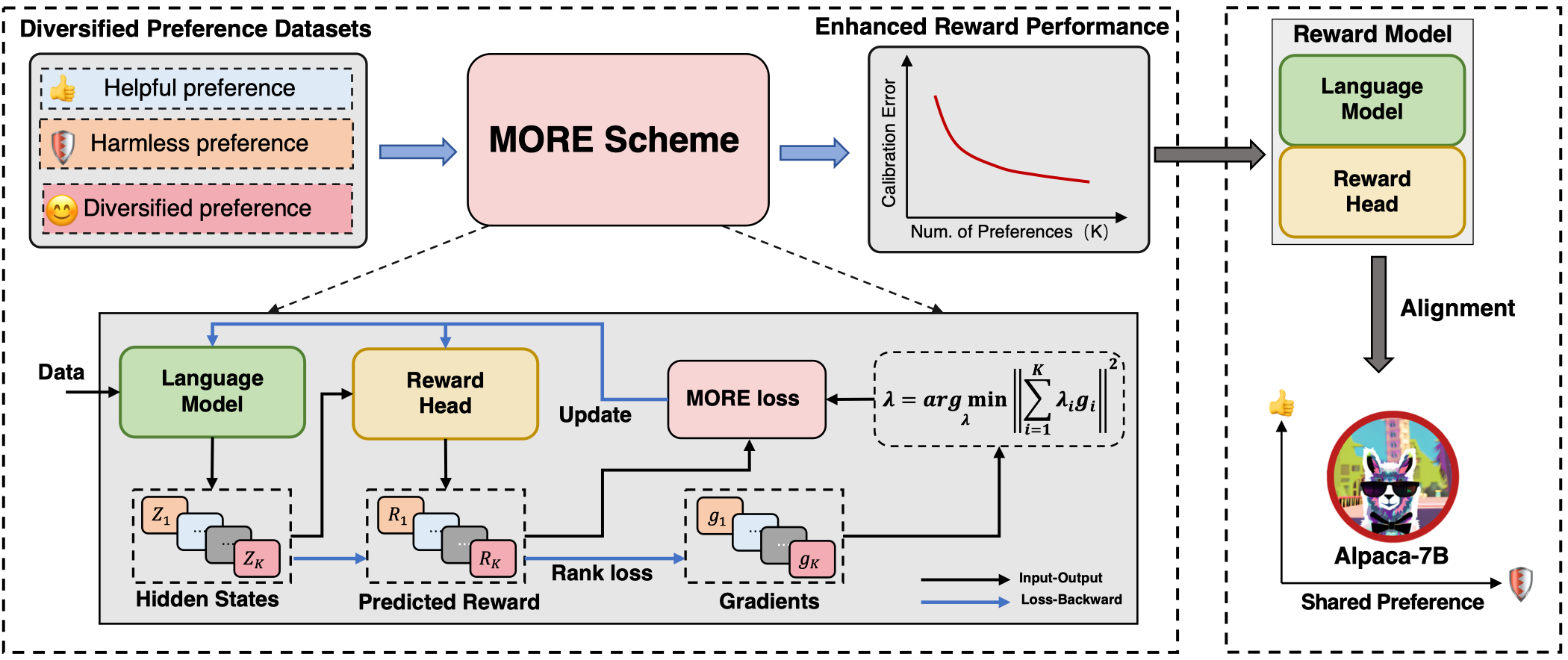
Aligning large language models (LLMs) with human preferences has been recognized as the key to improving LLMs' interaction quality. However, in this pluralistic world, human preferences can be diversified due to annotators' different tastes, which hinders the effectiveness of LLM alignment methods. This paper presents the first quantitative analysis of commonly used human feedback datasets to investigate the impact of diversified preferences on reward modeling. Our analysis reveals a correlation between the calibration performance of reward models (RMs) and the alignment performance of LLMs. We find that diversified preference data negatively affect the calibration performance of RMs on human-shared preferences, such as Harmless\&Helpful, thereby impairing the alignment performance of LLMs. To address the ineffectiveness, we propose a novel Multi-Objective Reward learning method (MORE) to enhance the calibration performance of RMs on shared preferences. We validate our findings by experiments on three models and five human preference datasets. Our method significantly improves the prediction calibration of RMs, leading to better alignment of the Alpaca-7B model with Harmless\&Helpful preferences. Furthermore, the connection between reward calibration and preference alignment performance suggests that calibration error can be adopted as a key metric for evaluating RMs. The open-source code and data are available at https://github.com/dunzeng/MORE.
PDF Abstract


