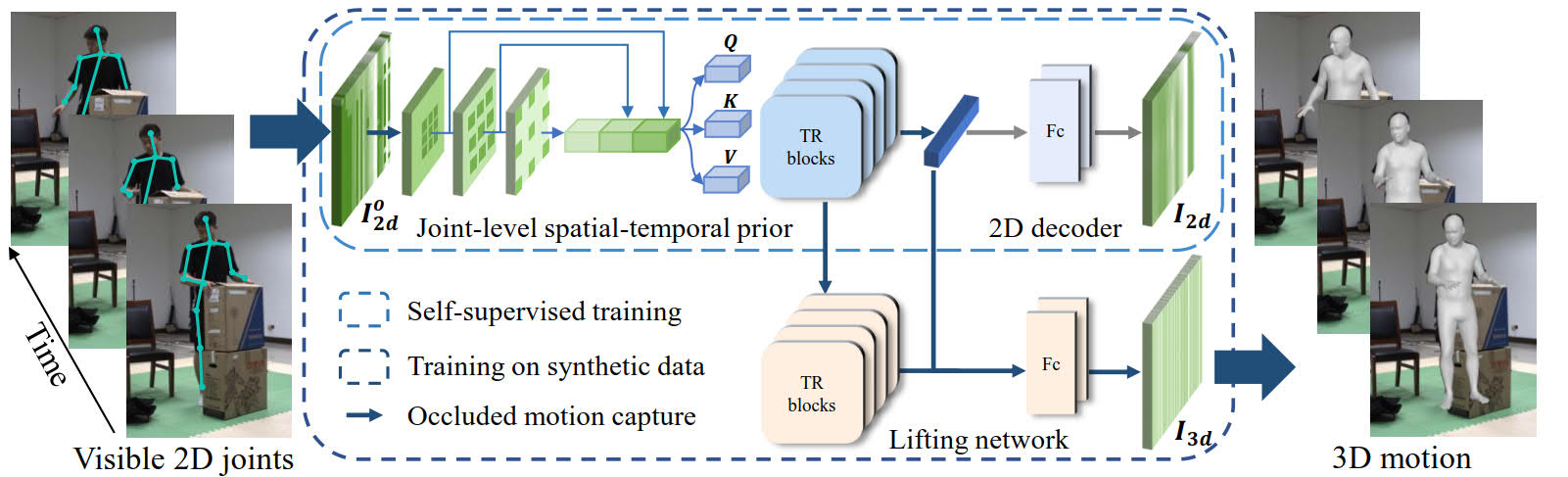
Occluded Human Body Capture with Self-Supervised Spatial-Temporal Motion Prior
Although significant progress has been achieved on monocular maker-less human motion capture in recent years, it is still hard for state-of-the-art methods to obtain satisfactory results in occlusion scenarios. There are two main reasons: the one is that the occluded motion capture is inherently ambiguous as various 3D poses can map to the same 2D observations, which always results in an unreliable estimation. The other is that no sufficient occluded human data can be used for training a robust model. To address the obstacles, our key-idea is to employ non-occluded human data to learn a joint-level spatial-temporal motion prior for occluded human with a self-supervised strategy. To further reduce the gap between synthetic and real occlusion data, we build the first 3D occluded motion dataset~(OcMotion), which can be used for both training and testing. We encode the motions in 2D maps and synthesize occlusions on non-occluded data for the self-supervised training. A spatial-temporal layer is then designed to learn joint-level correlations. The learned prior reduces the ambiguities of occlusions and is robust to diverse occlusion types, which is then adopted to assist the occluded human motion capture. Experimental results show that our method can generate accurate and coherent human motions from occluded videos with good generalization ability and runtime efficiency. The dataset and code are publicly available at \url{https://github.com/boycehbz/CHOMP}.
PDF Abstract


 Human3.6M
Human3.6M
 3DPW
3DPW
 MPI-INF-3DHP
MPI-INF-3DHP
 MuPoTS-3D
MuPoTS-3D
 AGORA
AGORA
 GPA
GPA
 3DOH50K
3DOH50K

