ObjectCompose: Evaluating Resilience of Vision-Based Models on Object-to-Background Compositional Changes
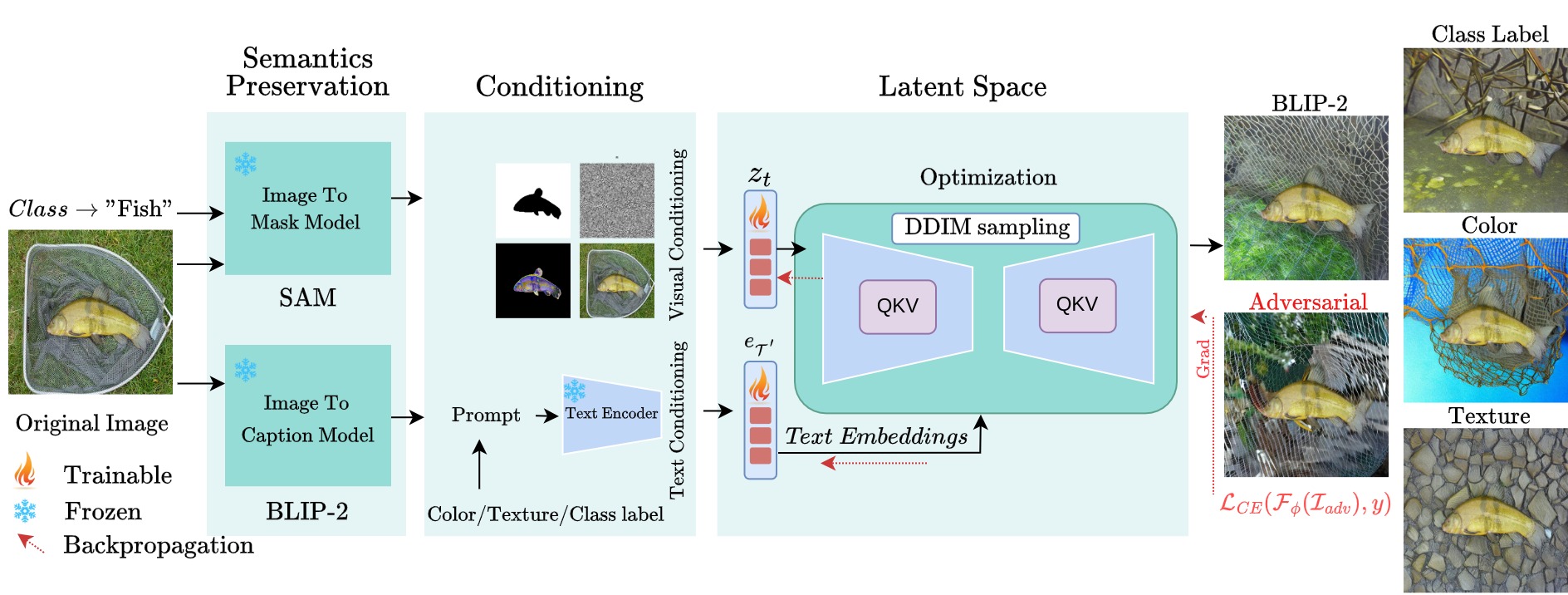
Given the large-scale multi-modal training of recent vision-based models and their generalization capabilities, understanding the extent of their robustness is critical for their real-world deployment. In this work, we evaluate the resilience of current vision-based models against diverse object-to-background context variations. The majority of robustness evaluation methods have introduced synthetic datasets to induce changes to object characteristics (viewpoints, scale, color) or utilized image transformation techniques (adversarial changes, common corruptions) on real images to simulate shifts in distributions. Recent works have explored leveraging large language models and diffusion models to generate changes in the background. However, these methods either lack in offering control over the changes to be made or distort the object semantics, making them unsuitable for the task. Our method, on the other hand, can induce diverse object-to-background changes while preserving the original semantics and appearance of the object. To achieve this goal, we harness the generative capabilities of text-to-image, image-to-text, and image-to-segment models to automatically generate a broad spectrum of object-to-background changes. We induce both natural and adversarial background changes by either modifying the textual prompts or optimizing the latents and textual embedding of text-to-image models. We produce various versions of standard vision datasets (ImageNet, COCO), incorporating either diverse and realistic backgrounds into the images or introducing color, texture, and adversarial changes in the background. We conduct extensive experiment to analyze the robustness of vision-based models against object-to-background context variations across diverse tasks. Code https://github.com/Muhammad-Huzaifaa/ObjectCompose.git
PDF Abstract

 ImageNet-B
ImageNet-B
 MS COCO
MS COCO
 Stylized ImageNet
Stylized ImageNet
