ObamaNet: Photo-realistic lip-sync from text
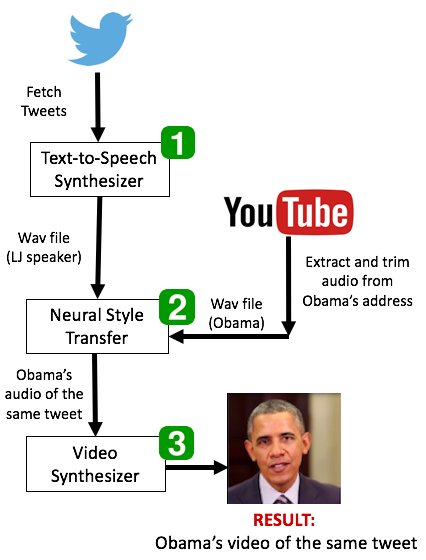
We present ObamaNet, the first architecture that generates both audio and synchronized photo-realistic lip-sync videos from any new text. Contrary to other published lip-sync approaches, ours is only composed of fully trainable neural modules and does not rely on any traditional computer graphics methods. More precisely, we use three main modules: a text-to-speech network based on Char2Wav, a time-delayed LSTM to generate mouth-keypoints synced to the audio, and a network based on Pix2Pix to generate the video frames conditioned on the keypoints.
PDF AbstractCode


Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
