NVC-Net: End-to-End Adversarial Voice Conversion
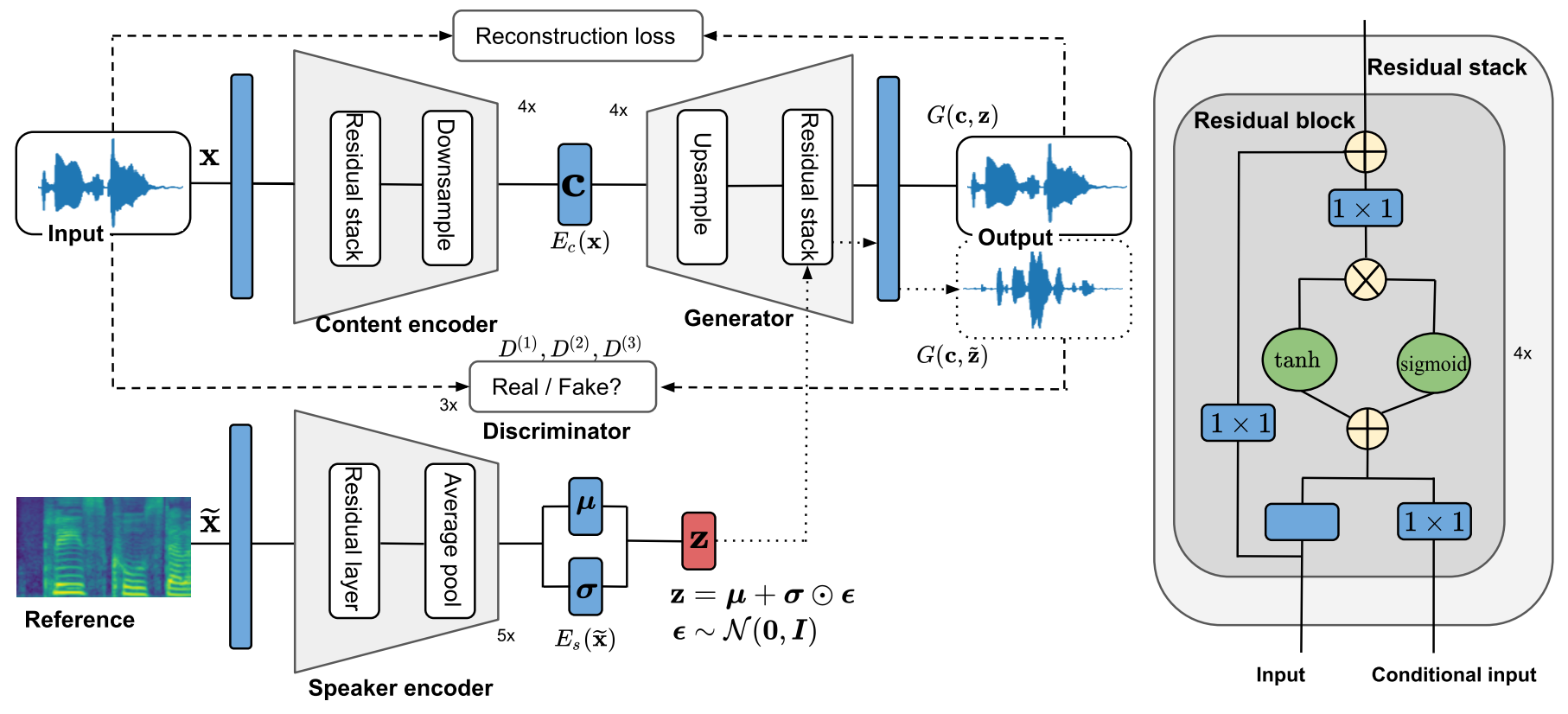
Voice conversion has gained increasing popularity in many applications of speech synthesis. The idea is to change the voice identity from one speaker into another while keeping the linguistic content unchanged. Many voice conversion approaches rely on the use of a vocoder to reconstruct the speech from acoustic features, and as a consequence, the speech quality heavily depends on such a vocoder. In this paper, we propose NVC-Net, an end-to-end adversarial network, which performs voice conversion directly on the raw audio waveform of arbitrary length. By disentangling the speaker identity from the speech content, NVC-Net is able to perform non-parallel traditional many-to-many voice conversion as well as zero-shot voice conversion from a short utterance of an unseen target speaker. Importantly, NVC-Net is non-autoregressive and fully convolutional, achieving fast inference. Our model is capable of producing samples at a rate of more than 3600 kHz on an NVIDIA V100 GPU, being orders of magnitude faster than state-of-the-art methods under the same hardware configurations. Objective and subjective evaluations on non-parallel many-to-many voice conversion tasks show that NVC-Net obtains competitive results with significantly fewer parameters.
PDF Abstract

