NeXt-TDNN: Modernizing Multi-Scale Temporal Convolution Backbone for Speaker Verification
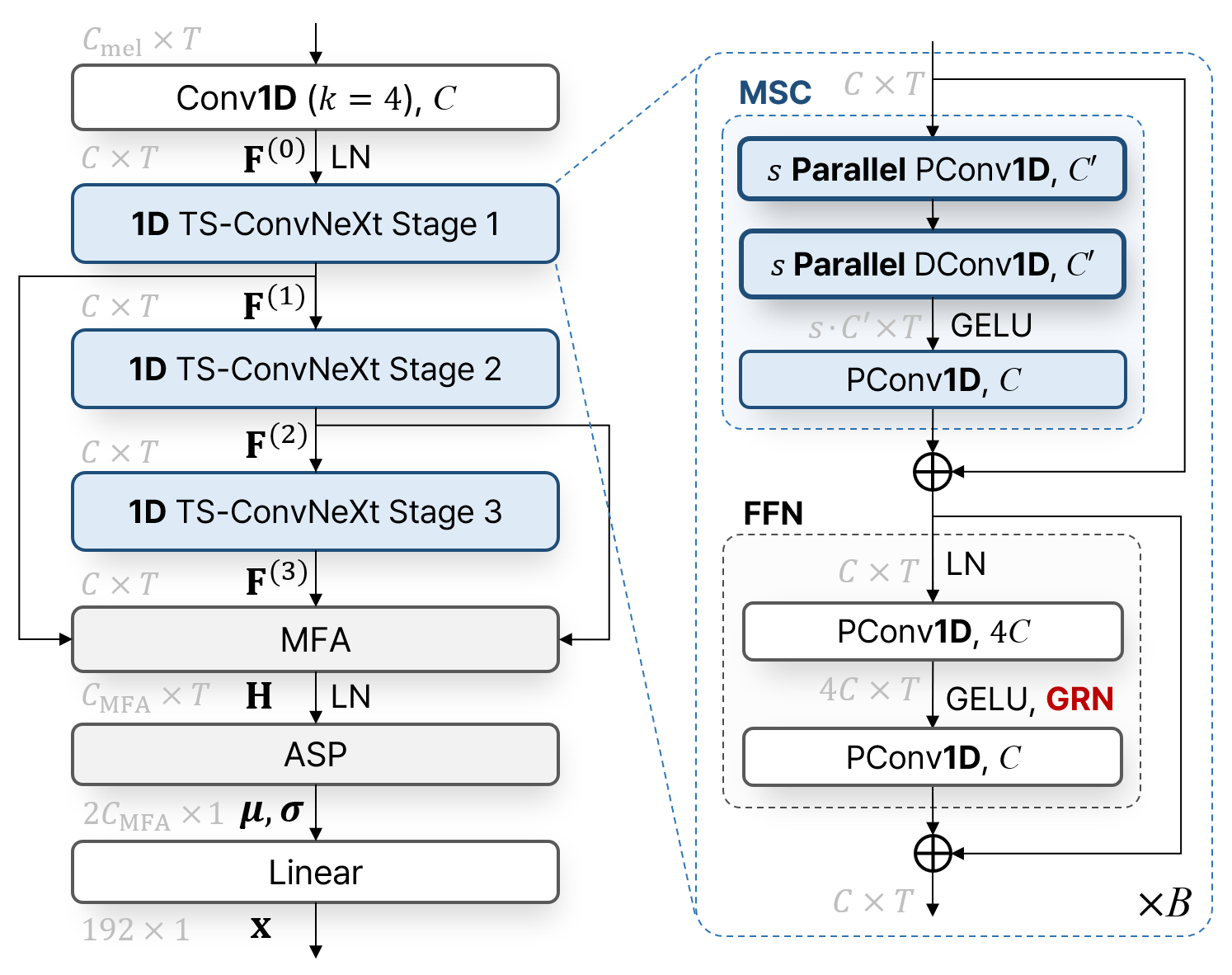
In speaker verification, ECAPA-TDNN has shown remarkable improvement by utilizing one-dimensional(1D) Res2Net block and squeeze-and-excitation(SE) module, along with multi-layer feature aggregation (MFA). Meanwhile, in vision tasks, ConvNet structures have been modernized by referring to Transformer, resulting in improved performance. In this paper, we present an improved block design for TDNN in speaker verification. Inspired by recent ConvNet structures, we replace the SE-Res2Net block in ECAPA-TDNN with a novel 1D two-step multi-scale ConvNeXt block, which we call TS-ConvNeXt. The TS-ConvNeXt block is constructed using two separated sub-modules: a temporal multi-scale convolution (MSC) and a frame-wise feed-forward network (FFN). This two-step design allows for flexible capturing of inter-frame and intra-frame contexts. Additionally, we introduce global response normalization (GRN) for the FFN modules to enable more selective feature propagation, similar to the SE module in ECAPA-TDNN. Experimental results demonstrate that NeXt-TDNN, with a modernized backbone block, significantly improved performance in speaker verification tasks while reducing parameter size and inference time. We have released our code for future studies.
PDF Abstract

 VoxCeleb1
VoxCeleb1
 VoxCeleb2
VoxCeleb2
