Neighbor-view Enhanced Model for Vision and Language Navigation
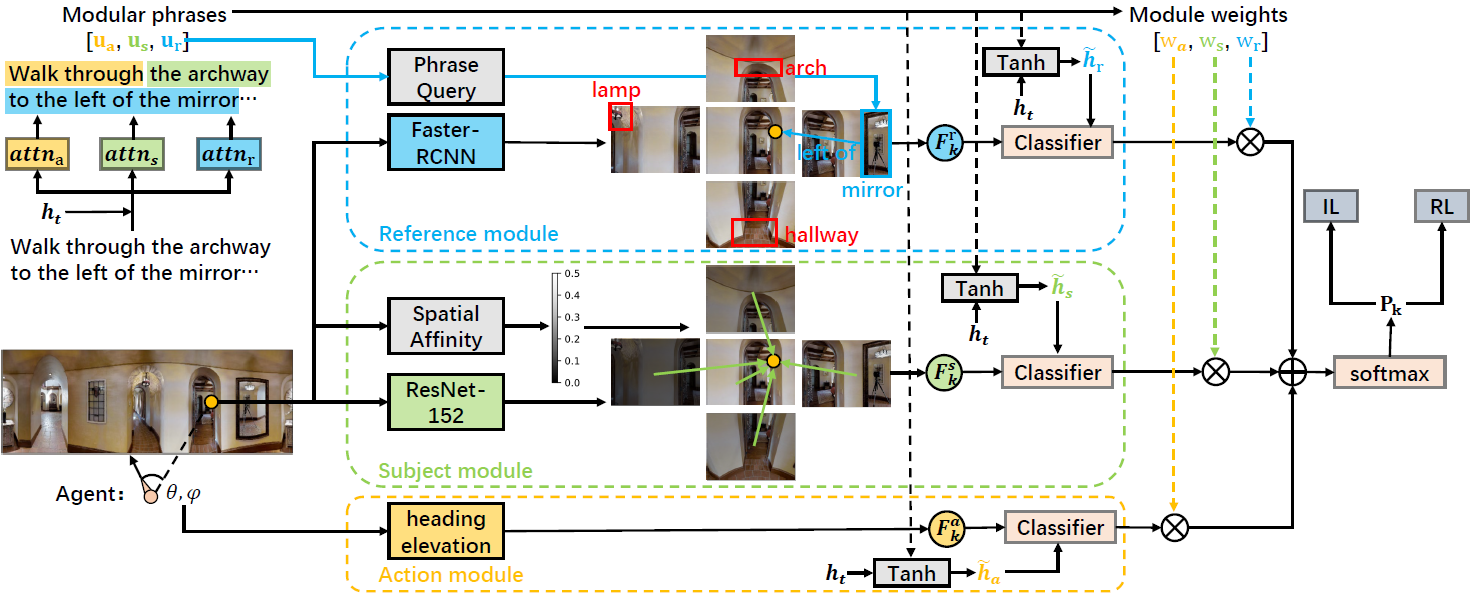
Vision and Language Navigation (VLN) requires an agent to navigate to a target location by following natural language instructions. Most of existing works represent a navigation candidate by the feature of the corresponding single view where the candidate lies in. However, an instruction may mention landmarks out of the single view as references, which might lead to failures of textual-visual matching of existing methods. In this work, we propose a multi-module Neighbor-View Enhanced Model (NvEM) to adaptively incorporate visual contexts from neighbor views for better textual-visual matching. Specifically, our NvEM utilizes a subject module and a reference module to collect contexts from neighbor views. The subject module fuses neighbor views at a global level, and the reference module fuses neighbor objects at a local level. Subjects and references are adaptively determined via attention me'chanisms. Our model also includes an action module to utilize the strong orientation guidance (e.g., "turn left") in instructions. Each module predicts navigation action separately and their weighted sum is used for predicting the final action. Extensive experimental results demonstrate the effectiveness of the proposed method on the R2R and R4R benchmarks against several state-of-the-art navigators, and NvEM even beats some pre-training ones. Our code is available at https://github.com/MarSaKi/NvEM.
PDF Abstract


