NAR-Former: Neural Architecture Representation Learning towards Holistic Attributes Prediction
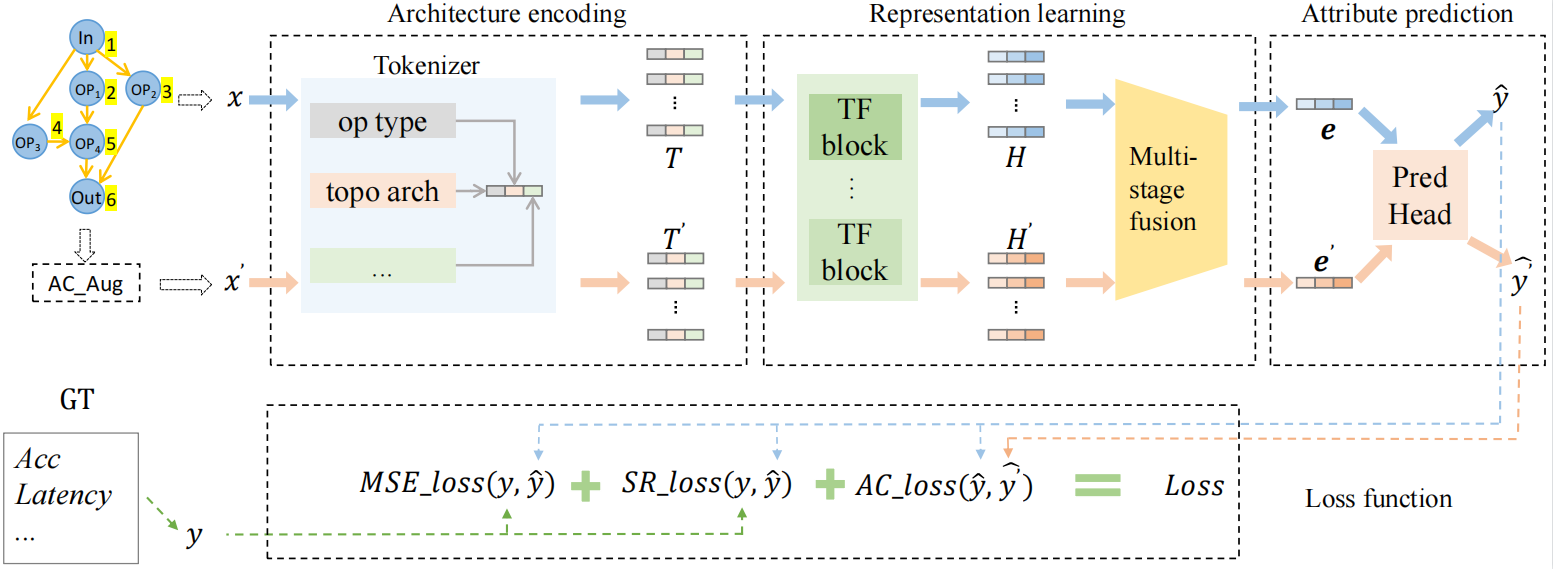
With the wide and deep adoption of deep learning models in real applications, there is an increasing need to model and learn the representations of the neural networks themselves. These models can be used to estimate attributes of different neural network architectures such as the accuracy and latency, without running the actual training or inference tasks. In this paper, we propose a neural architecture representation model that can be used to estimate these attributes holistically. Specifically, we first propose a simple and effective tokenizer to encode both the operation and topology information of a neural network into a single sequence. Then, we design a multi-stage fusion transformer to build a compact vector representation from the converted sequence. For efficient model training, we further propose an information flow consistency augmentation and correspondingly design an architecture consistency loss, which brings more benefits with less augmentation samples compared with previous random augmentation strategies. Experiment results on NAS-Bench-101, NAS-Bench-201, DARTS search space and NNLQP show that our proposed framework can be used to predict the aforementioned latency and accuracy attributes of both cell architectures and whole deep neural networks, and achieves promising performance. Code is available at https://github.com/yuny220/NAR-Former.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 NAS-Bench-201
NAS-Bench-201
 NAS-Bench-101
NAS-Bench-101
