Music Source Separation Based on a Lightweight Deep Learning Framework (DTTNET: DUAL-PATH TFC-TDF UNET)
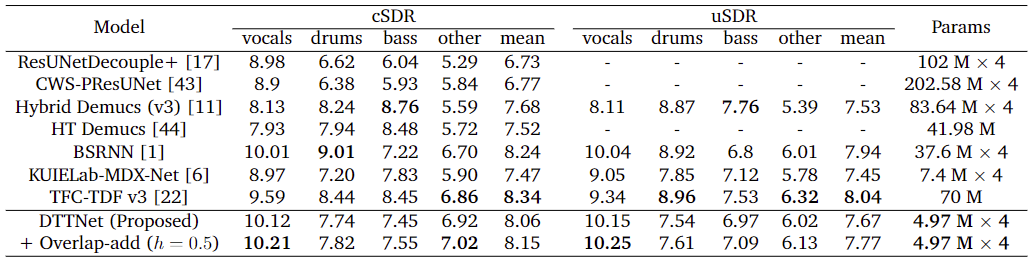
Music source separation (MSS) aims to extract 'vocals', 'drums', 'bass' and 'other' tracks from a piece of mixed music. While deep learning methods have shown impressive results, there is a trend toward larger models. In our paper, we introduce a novel and lightweight architecture called DTTNet, which is based on Dual-Path Module and Time-Frequency Convolutions Time-Distributed Fully-connected UNet (TFC-TDF UNet). DTTNet achieves 10.12 dB cSDR on 'vocals' compared to 10.01 dB reported for Bandsplit RNN (BSRNN) but with 86.7% fewer parameters. We also assess pattern-specific performance and model generalization for intricate audio patterns.
PDF Abstract

Tasks

Datasets
 MUSDB18
MUSDB18
 MUSDB18-HQ
MUSDB18-HQ

Methods
No methods listed for this paper. Add
relevant methods here
