Multimodal Question Answering for Unified Information Extraction
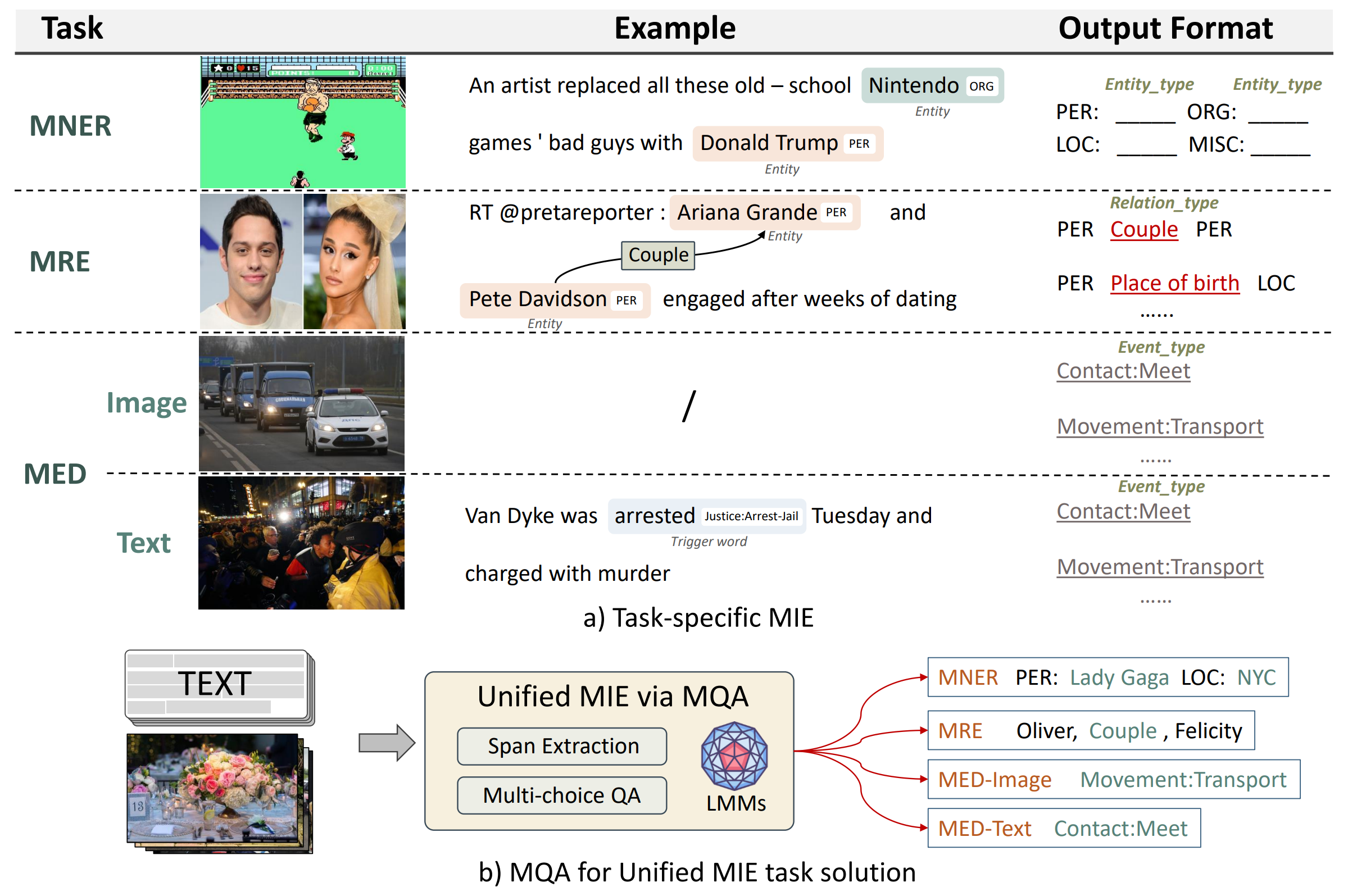
Multimodal information extraction (MIE) aims to extract structured information from unstructured multimedia content. Due to the diversity of tasks and settings, most current MIE models are task-specific and data-intensive, which limits their generalization to real-world scenarios with diverse task requirements and limited labeled data. To address these issues, we propose a novel multimodal question answering (MQA) framework to unify three MIE tasks by reformulating them into a unified span extraction and multi-choice QA pipeline. Extensive experiments on six datasets show that: 1) Our MQA framework consistently and significantly improves the performances of various off-the-shelf large multimodal models (LMM) on MIE tasks, compared to vanilla prompting. 2) In the zero-shot setting, MQA outperforms previous state-of-the-art baselines by a large margin. In addition, the effectiveness of our framework can successfully transfer to the few-shot setting, enhancing LMMs on a scale of 10B parameters to be competitive or outperform much larger language models such as ChatGPT and GPT-4. Our MQA framework can serve as a general principle of utilizing LMMs to better solve MIE and potentially other downstream multimodal tasks.
PDF Abstract

