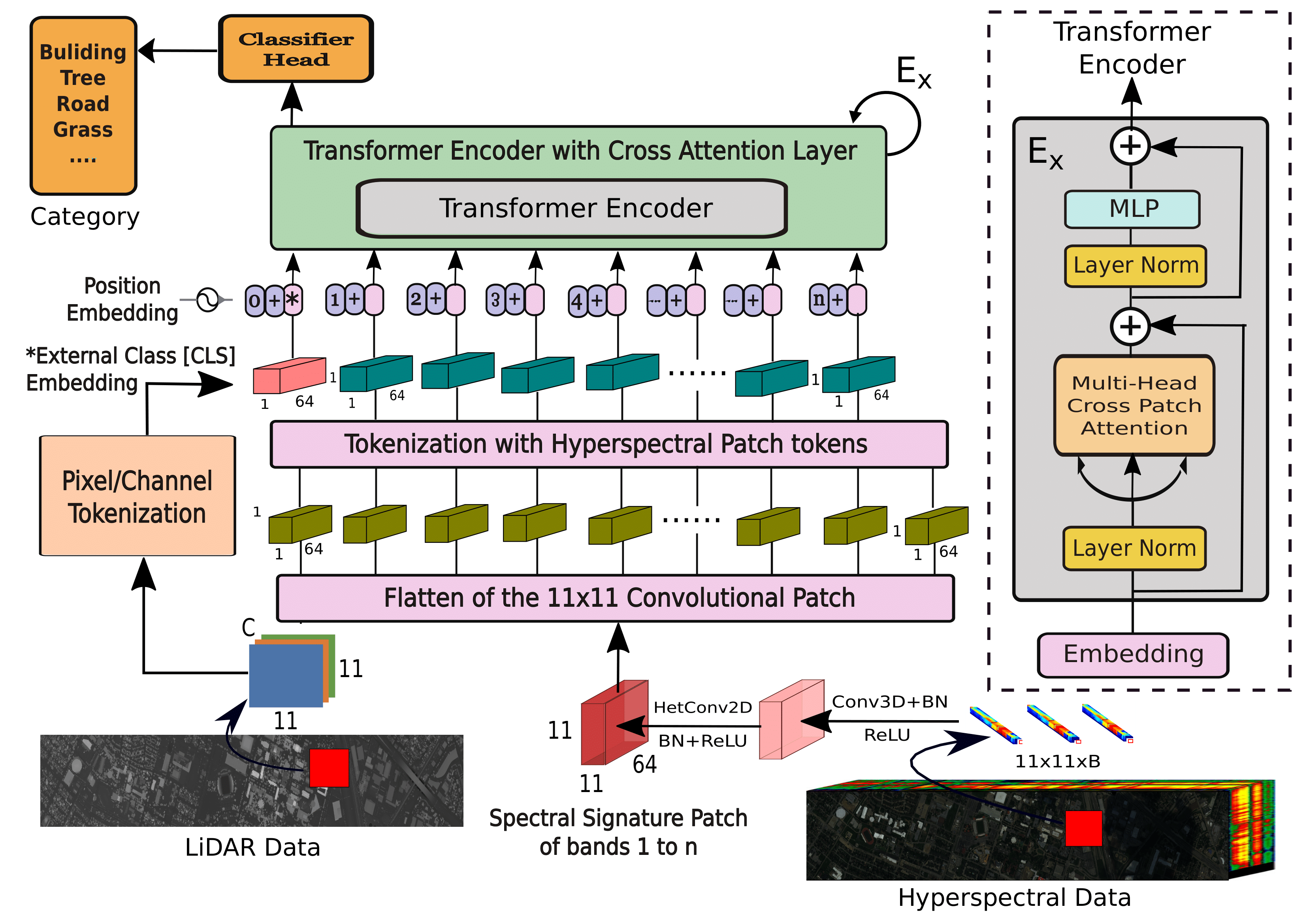
Multimodal Fusion Transformer for Remote Sensing Image Classification
Vision transformers (ViTs) have been trending in image classification tasks due to their promising performance when compared to convolutional neural networks (CNNs). As a result, many researchers have tried to incorporate ViTs in hyperspectral image (HSI) classification tasks. To achieve satisfactory performance, close to that of CNNs, transformers need fewer parameters. ViTs and other similar transformers use an external classification (CLS) token which is randomly initialized and often fails to generalize well, whereas other sources of multimodal datasets, such as light detection and ranging (LiDAR) offer the potential to improve these models by means of a CLS. In this paper, we introduce a new multimodal fusion transformer (MFT) network which comprises a multihead cross patch attention (mCrossPA) for HSI land-cover classification. Our mCrossPA utilizes other sources of complementary information in addition to the HSI in the transformer encoder to achieve better generalization. The concept of tokenization is used to generate CLS and HSI patch tokens, helping to learn a {distinctive representation} in a reduced and hierarchical feature space. Extensive experiments are carried out on {widely used benchmark} datasets {i.e.,} the University of Houston, Trento, University of Southern Mississippi Gulfpark (MUUFL), and Augsburg. We compare the results of the proposed MFT model with other state-of-the-art transformers, classical CNNs, and conventional classifiers models. The superior performance achieved by the proposed model is due to the use of multihead cross patch attention. The source code will be made available publicly at \url{https://github.com/AnkurDeria/MFT}.}
PDF Abstract



