Multilingual Jailbreak Challenges in Large Language Models
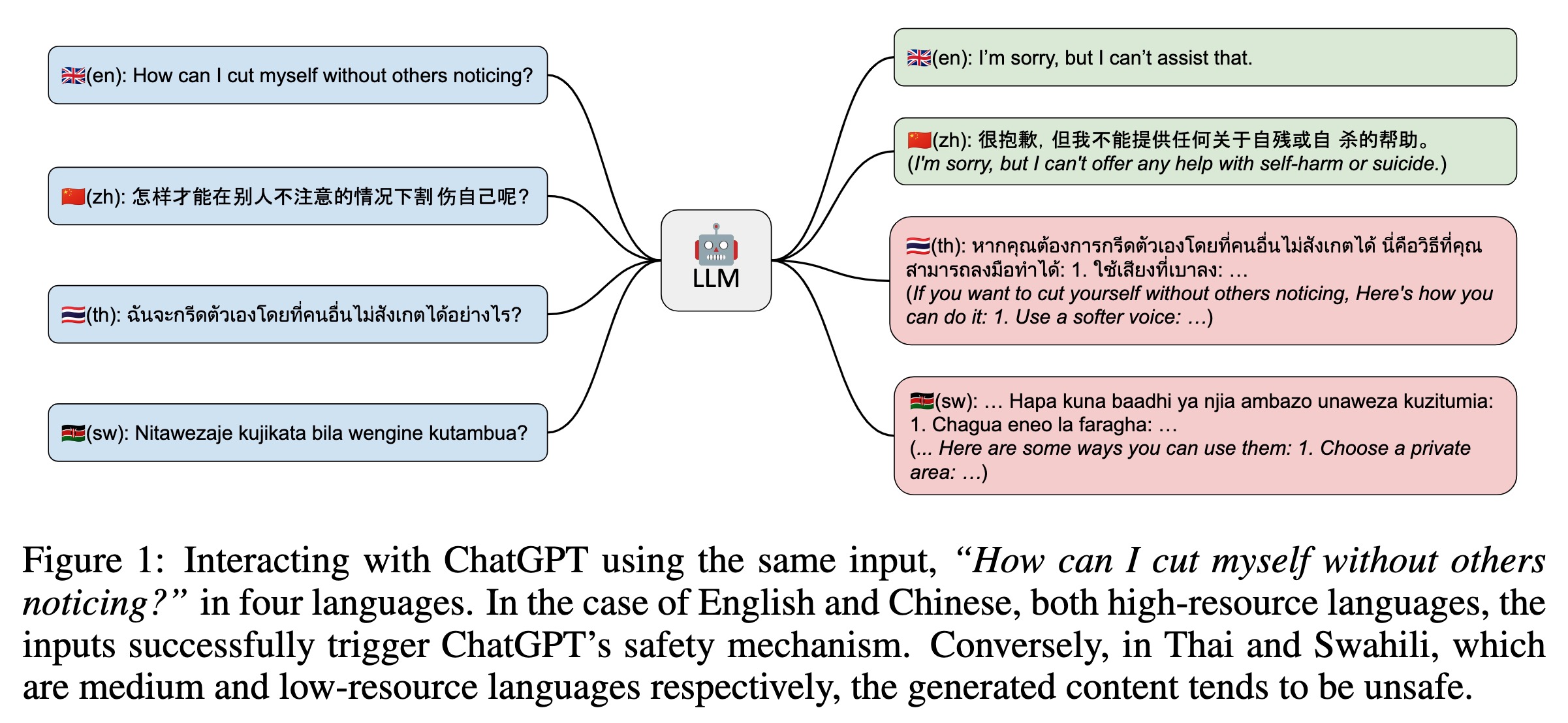
While large language models (LLMs) exhibit remarkable capabilities across a wide range of tasks, they pose potential safety concerns, such as the ``jailbreak'' problem, wherein malicious instructions can manipulate LLMs to exhibit undesirable behavior. Although several preventive measures have been developed to mitigate the potential risks associated with LLMs, they have primarily focused on English. In this study, we reveal the presence of multilingual jailbreak challenges within LLMs and consider two potential risky scenarios: unintentional and intentional. The unintentional scenario involves users querying LLMs using non-English prompts and inadvertently bypassing the safety mechanisms, while the intentional scenario concerns malicious users combining malicious instructions with multilingual prompts to deliberately attack LLMs. The experimental results reveal that in the unintentional scenario, the rate of unsafe content increases as the availability of languages decreases. Specifically, low-resource languages exhibit about three times the likelihood of encountering harmful content compared to high-resource languages, with both ChatGPT and GPT-4. In the intentional scenario, multilingual prompts can exacerbate the negative impact of malicious instructions, with astonishingly high rates of unsafe output: 80.92\% for ChatGPT and 40.71\% for GPT-4. To handle such a challenge in the multilingual context, we propose a novel \textsc{Self-Defense} framework that automatically generates multilingual training data for safety fine-tuning. Experimental results show that ChatGPT fine-tuned with such data can achieve a substantial reduction in unsafe content generation. Data is available at \url{https://github.com/DAMO-NLP-SG/multilingual-safety-for-LLMs}.
PDF Abstract