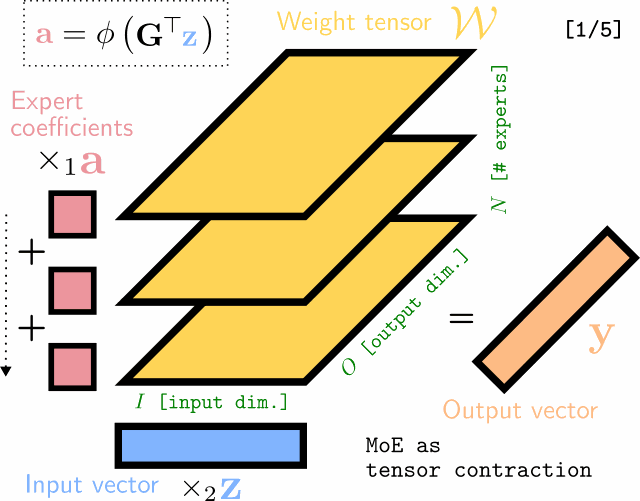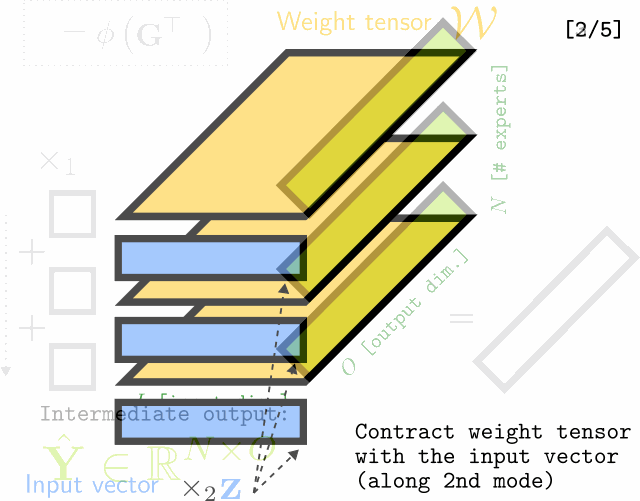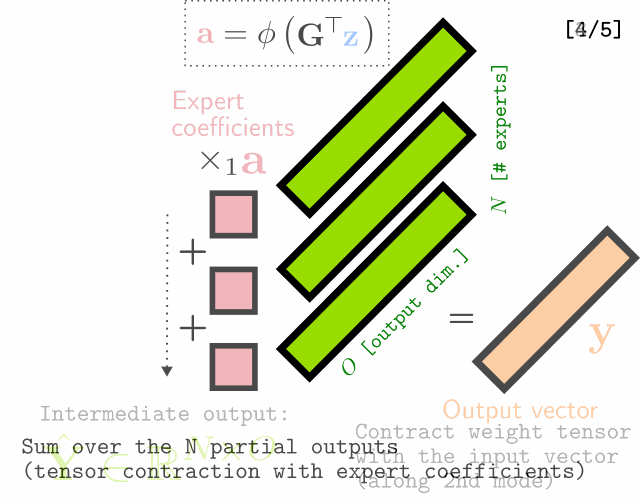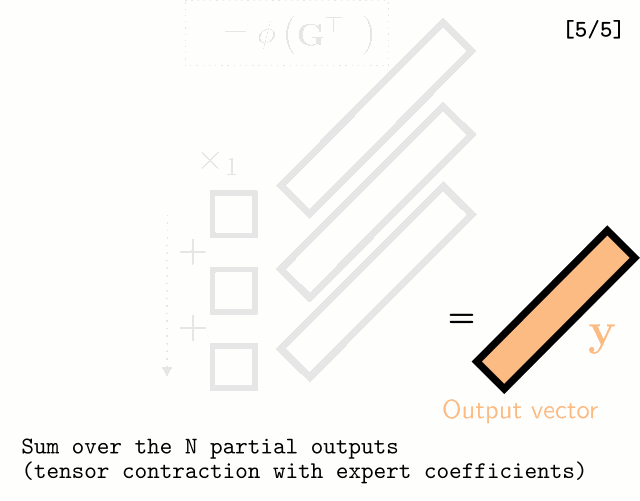
Multilinear Mixture of Experts: Scalable Expert Specialization through Factorization
The Mixture of Experts (MoE) paradigm provides a powerful way to decompose inscrutable dense layers into smaller, modular computations often more amenable to human interpretation, debugging, and editability. A major problem however lies in the computational cost of scaling the number of experts to achieve sufficiently fine-grained specialization. In this paper, we propose the Multilinear Mixutre of Experts (MMoE) layer to address this, focusing on vision models. MMoE layers perform an implicit computation on prohibitively large weight tensors entirely in factorized form. Consequently, MMoEs both (1) avoid the issues incurred through the discrete expert routing in the popular 'sparse' MoE models, yet (2) do not incur the restrictively high inference-time costs of 'soft' MoE alternatives. We present both qualitative and quantitative evidence (through visualization and counterfactual interventions respectively) that scaling MMoE layers when fine-tuning foundation models for vision tasks leads to more specialized experts at the class-level whilst remaining competitive with the performance of parameter-matched linear layer counterparts. Finally, we show that learned expert specialism further facilitates manual correction of demographic bias in CelebA attribute classification. Our MMoE model code is available at https://github.com/james-oldfield/MMoE.
PDF Abstract

 ImageNet
ImageNet
 CelebA
CelebA
