Multi3WOZ: A Multilingual, Multi-Domain, Multi-Parallel Dataset for Training and Evaluating Culturally Adapted Task-Oriented Dialog Systems
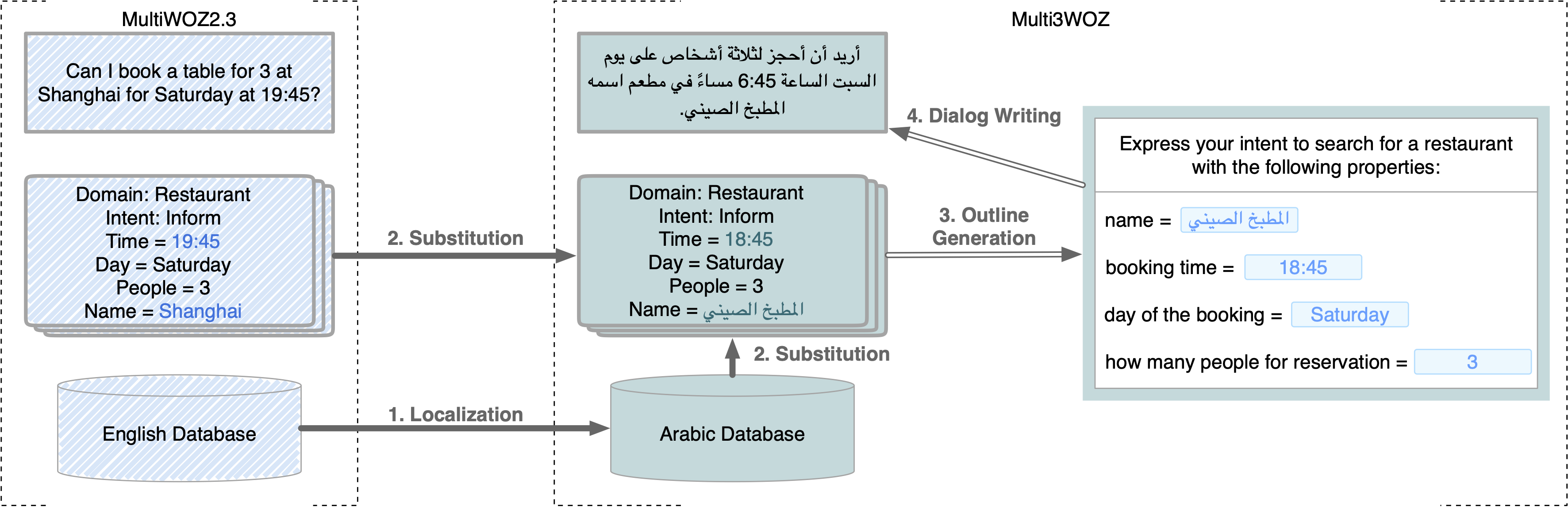
Creating high-quality annotated data for task-oriented dialog (ToD) is known to be notoriously difficult, and the challenges are amplified when the goal is to create equitable, culturally adapted, and large-scale ToD datasets for multiple languages. Therefore, the current datasets are still very scarce and suffer from limitations such as translation-based non-native dialogs with translation artefacts, small scale, or lack of cultural adaptation, among others. In this work, we first take stock of the current landscape of multilingual ToD datasets, offering a systematic overview of their properties and limitations. Aiming to reduce all the detected limitations, we then introduce Multi3WOZ, a novel multilingual, multi-domain, multi-parallel ToD dataset. It is large-scale and offers culturally adapted dialogs in 4 languages to enable training and evaluation of multilingual and cross-lingual ToD systems. We describe a complex bottom-up data collection process that yielded the final dataset, and offer the first sets of baseline scores across different ToD-related tasks for future reference, also highlighting its challenging nature.
PDF Abstract
 BiToD
BiToD
