Multi-View Attention Network for Visual Dialog
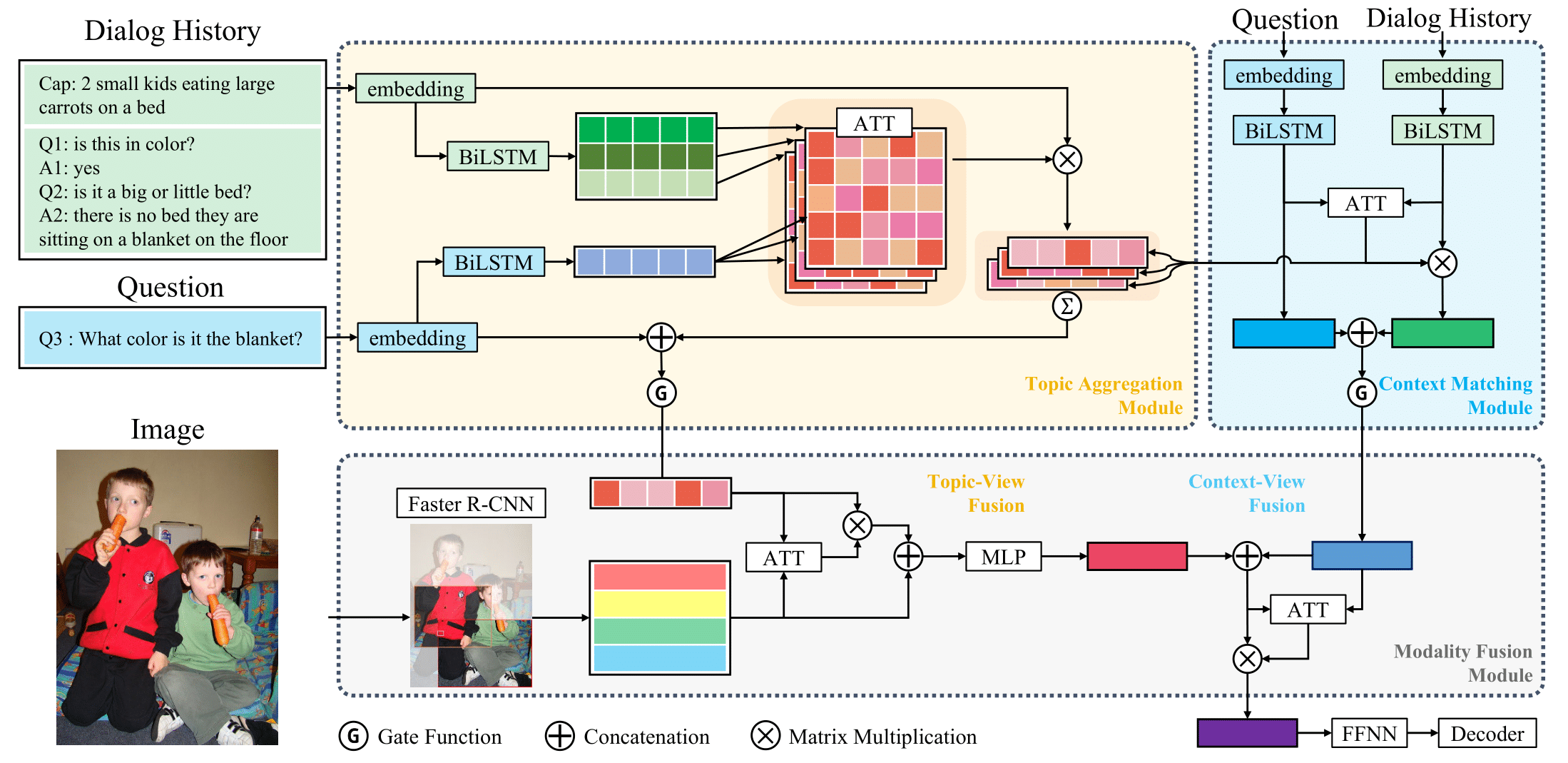
Visual dialog is a challenging vision-language task in which a series of questions visually grounded by a given image are answered. To resolve the visual dialog task, a high-level understanding of various multimodal inputs (e.g., question, dialog history, and image) is required. Specifically, it is necessary for an agent to 1) determine the semantic intent of question and 2) align question-relevant textual and visual contents among heterogeneous modality inputs. In this paper, we propose Multi-View Attention Network (MVAN), which leverages multiple views about heterogeneous inputs based on attention mechanisms. MVAN effectively captures the question-relevant information from the dialog history with two complementary modules (i.e., Topic Aggregation and Context Matching), and builds multimodal representations through sequential alignment processes (i.e., Modality Alignment). Experimental results on VisDial v1.0 dataset show the effectiveness of our proposed model, which outperforms the previous state-of-the-art methods with respect to all evaluation metrics.
PDF Abstract

 VisDial
VisDial

