Multi-scale Hierarchical Vision Transformer with Cascaded Attention Decoding for Medical Image Segmentation
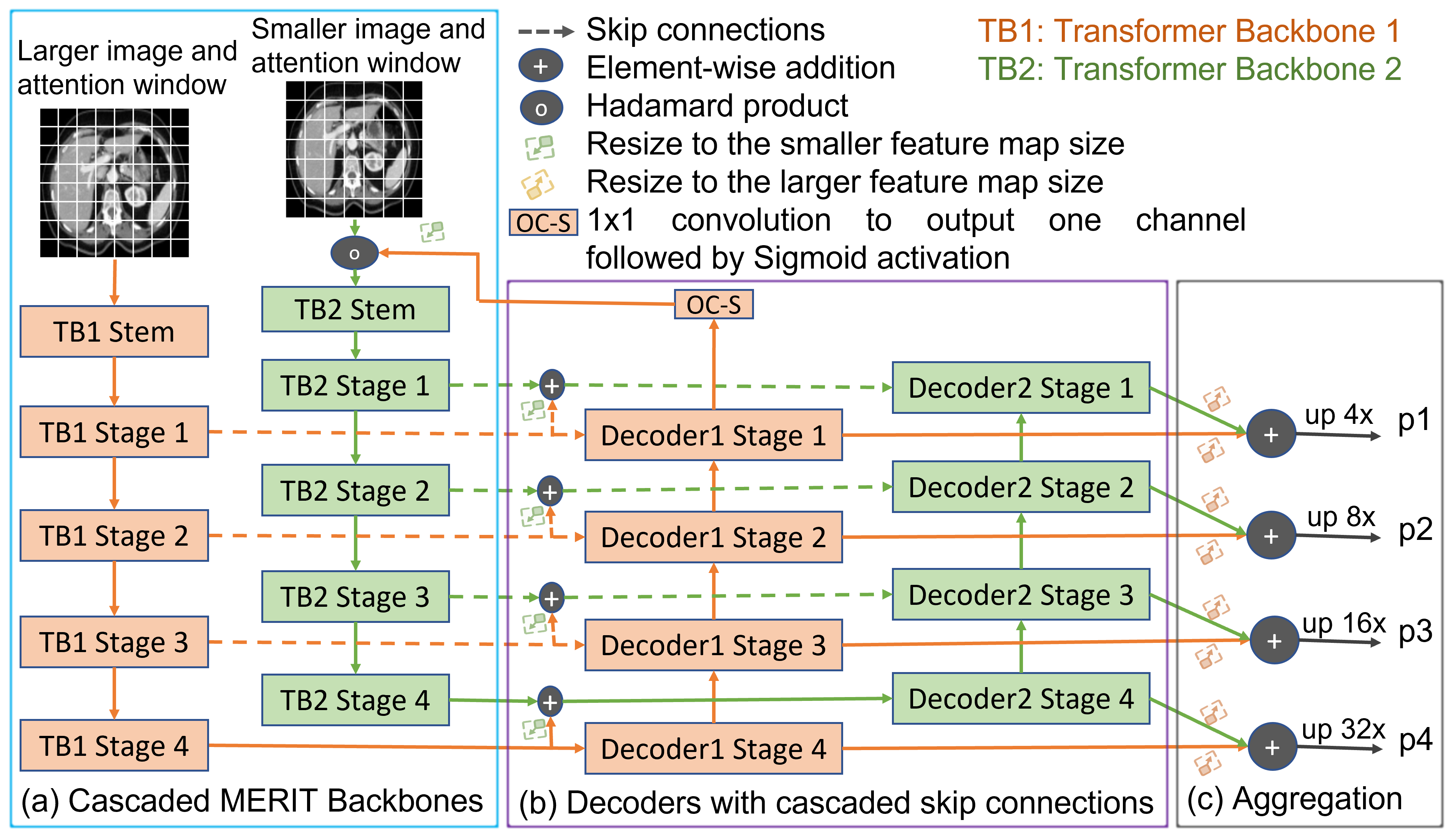
Transformers have shown great success in medical image segmentation. However, transformers may exhibit a limited generalization ability due to the underlying single-scale self-attention (SA) mechanism. In this paper, we address this issue by introducing a Multi-scale hiERarchical vIsion Transformer (MERIT) backbone network, which improves the generalizability of the model by computing SA at multiple scales. We also incorporate an attention-based decoder, namely Cascaded Attention Decoding (CASCADE), for further refinement of multi-stage features generated by MERIT. Finally, we introduce an effective multi-stage feature mixing loss aggregation (MUTATION) method for better model training via implicit ensembling. Our experiments on two widely used medical image segmentation benchmarks (i.e., Synapse Multi-organ, ACDC) demonstrate the superior performance of MERIT over state-of-the-art methods. Our MERIT architecture and MUTATION loss aggregation can be used with downstream medical image and semantic segmentation tasks.
PDF Abstract



 ACDC
ACDC
 MICCAI 2015 Multi-Atlas Abdomen Labeling Challenge
MICCAI 2015 Multi-Atlas Abdomen Labeling Challenge

