Multi-lingual Evaluation of Code Generation Models
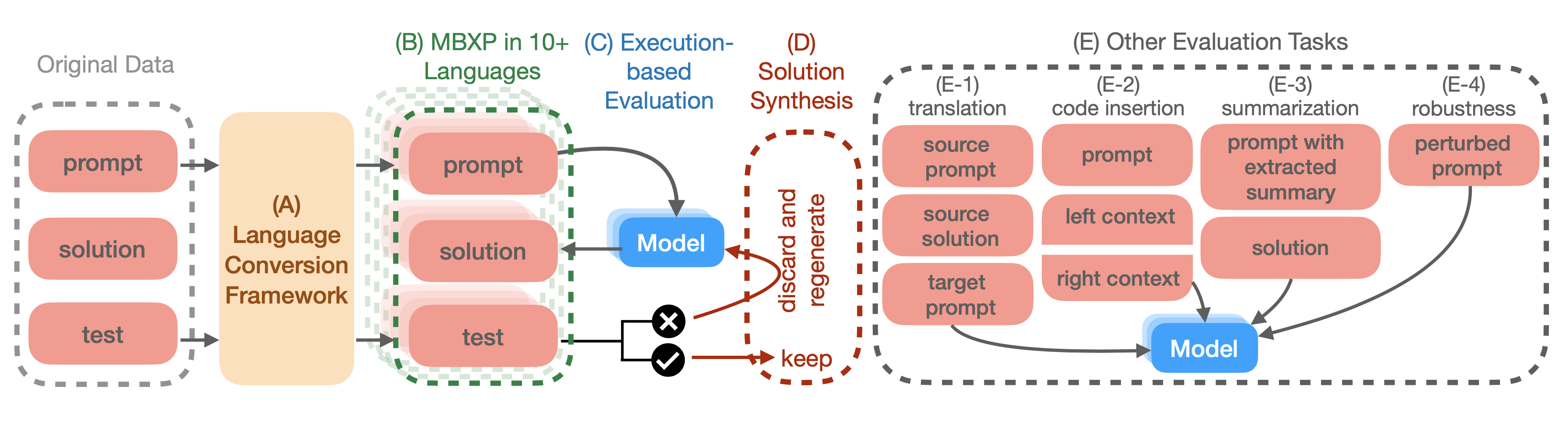
We present new benchmarks on evaluation code generation models: MBXP and Multilingual HumanEval, and MathQA-X. These datasets cover over 10 programming languages and are generated using a scalable conversion framework that transpiles prompts and test cases from the original Python datasets into the corresponding data in the target language. Using these benchmarks, we are able to assess the performance of code generation models in a multi-lingual fashion, and discovered generalization ability of language models on out-of-domain languages, advantages of multi-lingual models over mono-lingual, the ability of few-shot prompting to teach the model new languages, and zero-shot translation abilities even on mono-lingual settings. Furthermore, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages, which can be used for other code-related evaluations such as code insertion, robustness, or summarization tasks. Overall, our benchmarks represents a significant step towards a deeper understanding of language models' code generation abilities. We publicly release our code and datasets at https://github.com/amazon-research/mxeval.
PDF Abstract

 HumanEval
HumanEval
