Multi-Label Knowledge Distillation
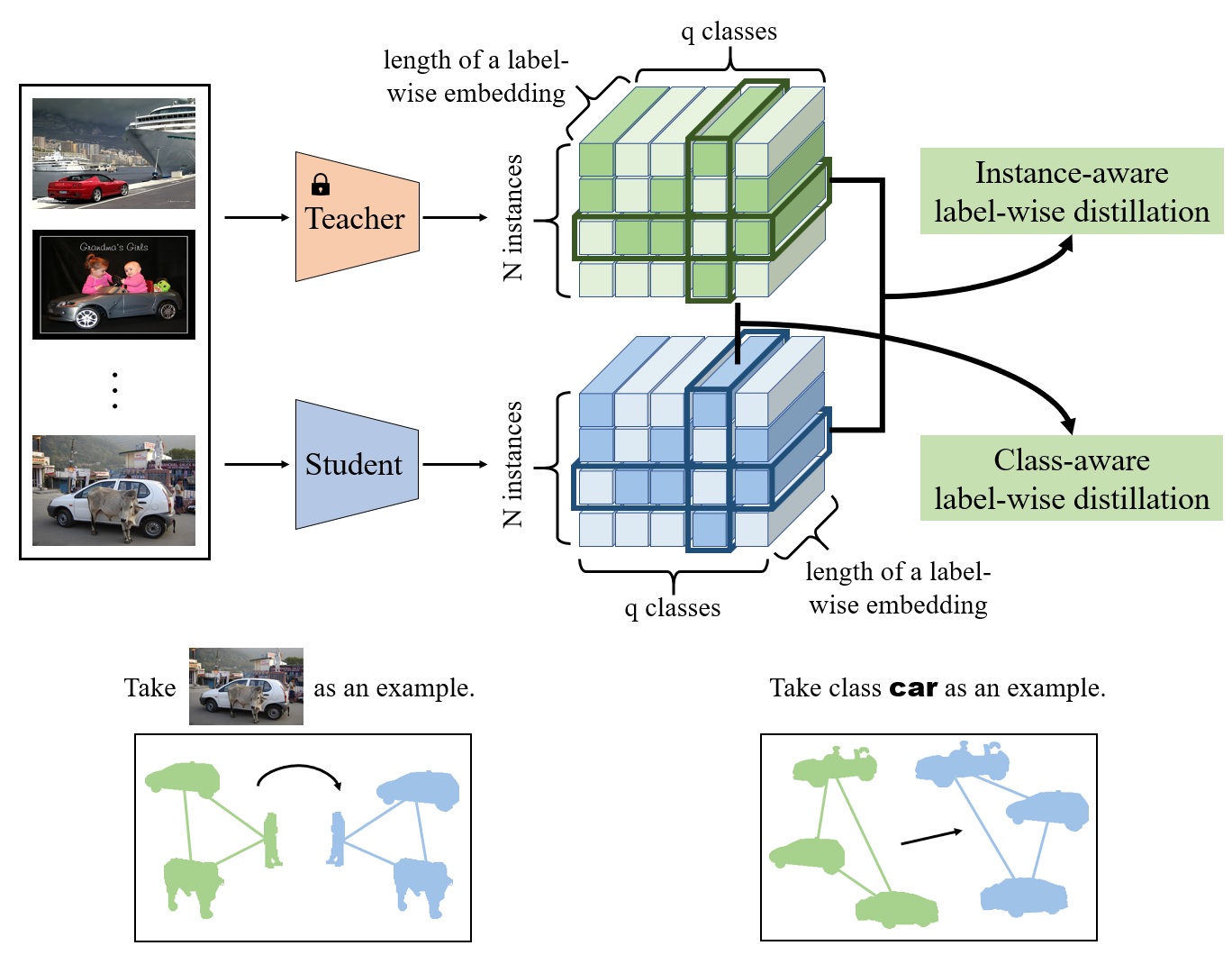
Existing knowledge distillation methods typically work by imparting the knowledge of output logits or intermediate feature maps from the teacher network to the student network, which is very successful in multi-class single-label learning. However, these methods can hardly be extended to the multi-label learning scenario, where each instance is associated with multiple semantic labels, because the prediction probabilities do not sum to one and feature maps of the whole example may ignore minor classes in such a scenario. In this paper, we propose a novel multi-label knowledge distillation method. On one hand, it exploits the informative semantic knowledge from the logits by dividing the multi-label learning problem into a set of binary classification problems; on the other hand, it enhances the distinctiveness of the learned feature representations by leveraging the structural information of label-wise embeddings. Experimental results on multiple benchmark datasets validate that the proposed method can avoid knowledge counteraction among labels, thus achieving superior performance against diverse comparing methods. Our code is available at: https://github.com/penghui-yang/L2D
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


 MS COCO
MS COCO
 NUS-WIDE
NUS-WIDE
