Multi-granularity Correspondence Learning from Long-term Noisy Videos
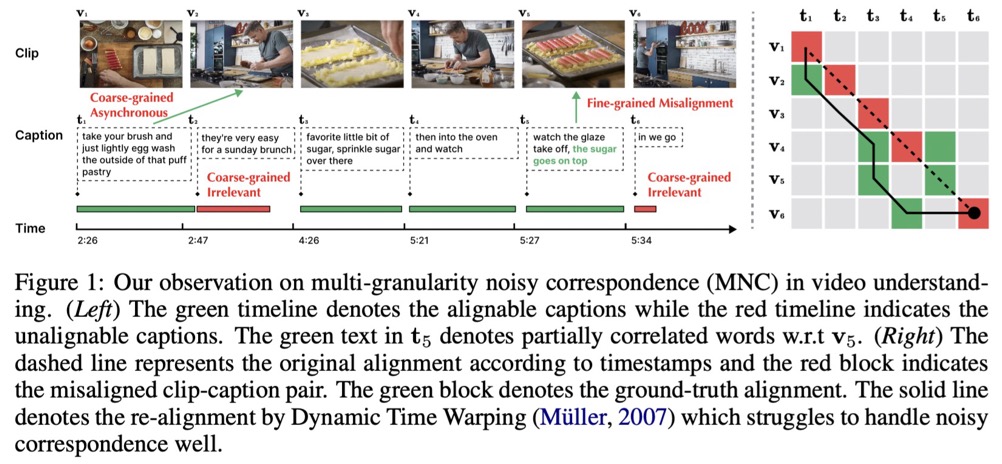
Existing video-language studies mainly focus on learning short video clips, leaving long-term temporal dependencies rarely explored due to over-high computational cost of modeling long videos. To address this issue, one feasible solution is learning the correspondence between video clips and captions, which however inevitably encounters the multi-granularity noisy correspondence (MNC) problem. To be specific, MNC refers to the clip-caption misalignment (coarse-grained) and frame-word misalignment (fine-grained), hindering temporal learning and video understanding. In this paper, we propose NOise Robust Temporal Optimal traNsport (Norton) that addresses MNC in a unified optimal transport (OT) framework. In brief, Norton employs video-paragraph and clip-caption contrastive losses to capture long-term dependencies based on OT. To address coarse-grained misalignment in video-paragraph contrast, Norton filters out the irrelevant clips and captions through an alignable prompt bucket and realigns asynchronous clip-caption pairs based on transport distance. To address the fine-grained misalignment, Norton incorporates a soft-maximum operator to identify crucial words and key frames. Additionally, Norton exploits the potential faulty negative samples in clip-caption contrast by rectifying the alignment target with OT assignment to ensure precise temporal modeling. Extensive experiments on video retrieval, videoQA, and action segmentation verify the effectiveness of our method. Code is available at https://lin-yijie.github.io/projects/Norton.
PDF AbstractCode


 MSR-VTT
MSR-VTT
 HowTo100M
HowTo100M
 YouCook2
YouCook2

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Action Segmentation | COIN | Norton | Frame accuracy | 69.8 | # 3 | ||
| Zero-Shot Video Retrieval | MSR-VTT | Norton | text-to-video R@1 | 10.7 | # 30 | ||
| text-to-video R@5 | 24.1 | # 30 | |||||
| Video Question Answering | MSRVTT-MC | Norton | Accuracy | 92.7 | # 6 | ||
| Zero-Shot Video Retrieval | YouCook2 | Norton | text-to-video R@1 | 24.2 | # 1 | ||
| text-to-video R@5 | 51.9 | # 1 | |||||
| text-to-video R@10 | 64.1 | # 1 | |||||
| Long Video Retrieval (Background Removed) | YouCook2 | Norton | Cap. Avg. R@1 | 75.5 | # 1 | ||
| Cap. Avg. R@5 | 95.0 | # 1 | |||||
| Cap. Avg. R@10 | 97.7 | # 2 | |||||
| DTW R@1 | 88.7 | # 1 | |||||
| DTW R@5 | 98.8 | # 1 | |||||
| DTW R@10 | 99.5 | # 1 | |||||
| OTAM R@1 | 88.9 | # 1 | |||||
| OTAM R@5 | 98.4 | # 1 | |||||
| OTAM R@10 | 99.5 | # 1 |
