MuDPT: Multi-modal Deep-symphysis Prompt Tuning for Large Pre-trained Vision-Language Models
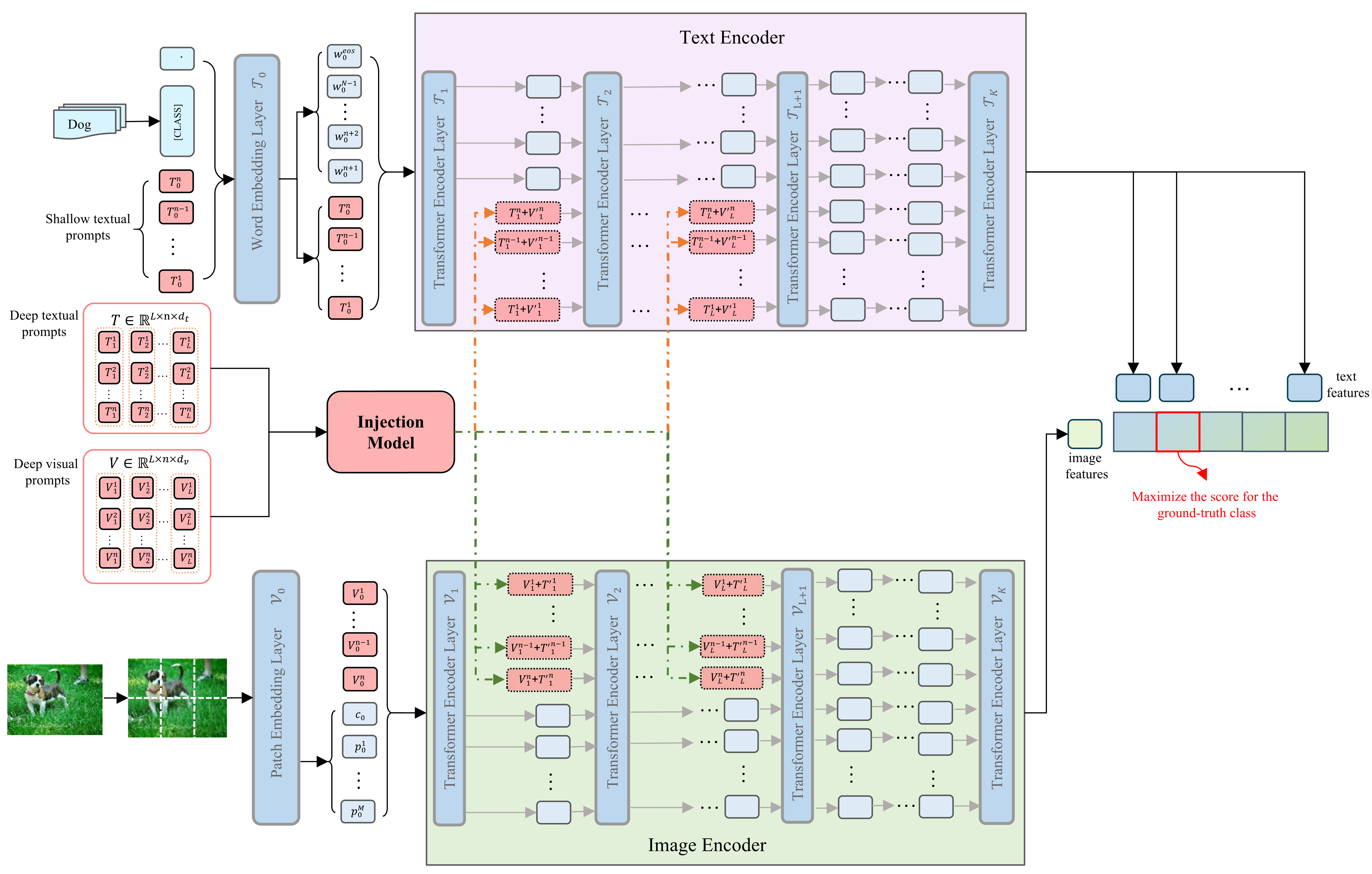
Prompt tuning, like CoOp, has recently shown promising vision recognizing and transfer learning ability on various downstream tasks with the emergence of large pre-trained vision-language models like CLIP. However, we identify that existing uni-modal prompt tuning approaches may result in sub-optimal performance since this uni-modal design breaks the original alignment of textual and visual representations in the pre-trained model. Inspired by the nature of pre-trained vision-language models, we aim to achieve completeness in prompt tuning and propose a novel approach called Multi-modal Deep-symphysis Prompt Tuning, dubbed as MuDPT, which extends independent multi-modal prompt tuning by additionally learning a model-agnostic transformative network to allow deep hierarchical bi-directional prompt fusion. We evaluate the effectiveness of MuDPT on few-shot vision recognition and out-of-domain generalization tasks. Compared with the state-of-the-art methods, MuDPT achieves better recognition and generalization ability with an apparent margin thanks to synergistic alignment of textual and visual representations. Our code is available at: https://github.com/Mechrev0/MuDPT.
PDF Abstract


 ImageNet
ImageNet
