Moviescope: Large-scale Analysis of Movies using Multiple Modalities
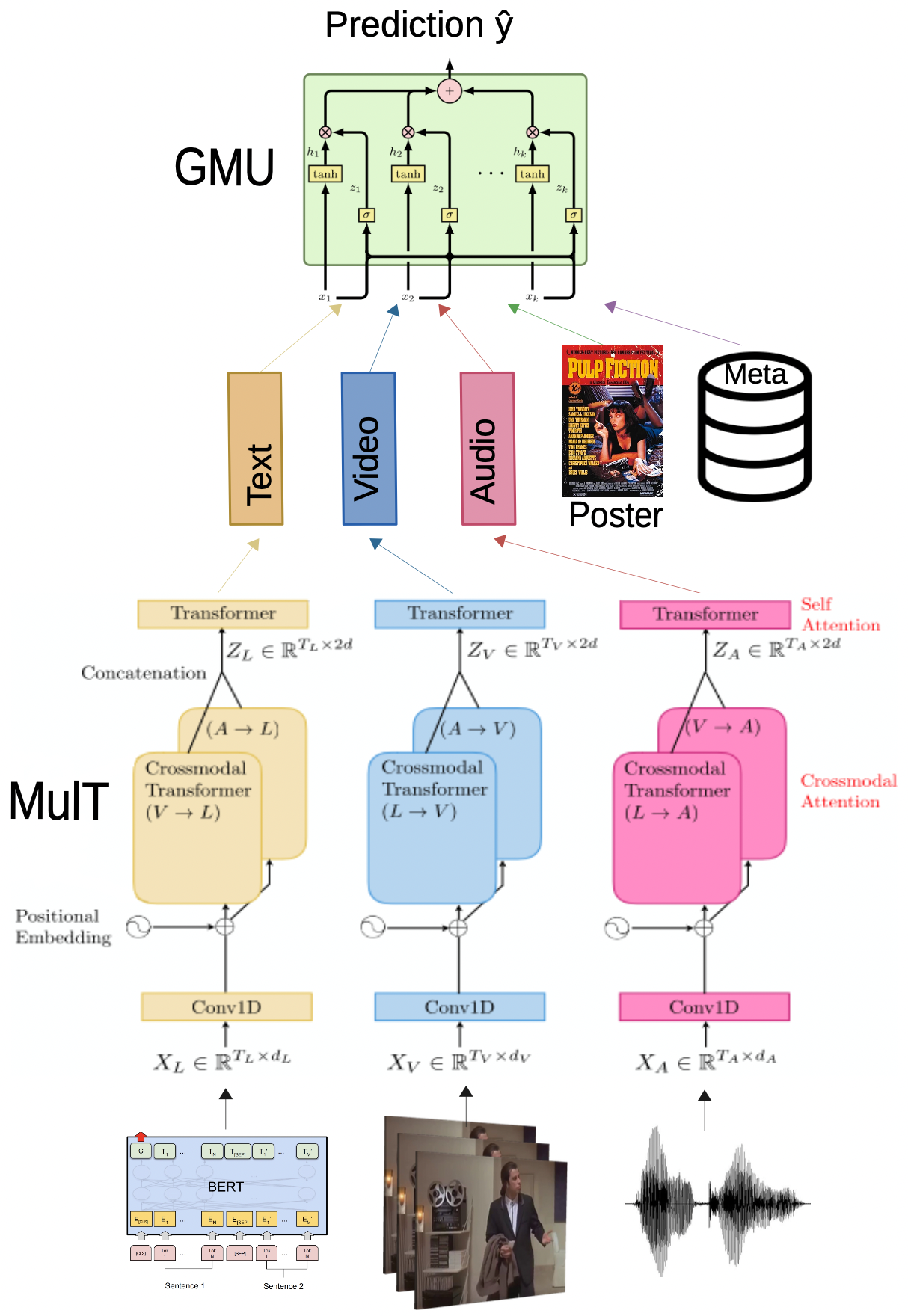
Film media is a rich form of artistic expression. Unlike photography, and short videos, movies contain a storyline that is deliberately complex and intricate in order to engage its audience. In this paper we present a large scale study comparing the effectiveness of visual, audio, text, and metadata-based features for predicting high-level information about movies such as their genre or estimated budget. We demonstrate the usefulness of content-based methods in this domain in contrast to human-based and metadata-based predictions in the era of deep learning. Additionally, we provide a comprehensive study of temporal feature aggregation methods for representing video and text and find that simple pooling operations are effective in this domain. We also show to what extent different modalities are complementary to each other. To this end, we also introduce Moviescope, a new large-scale dataset of 5,000 movies with corresponding movie trailers (video + audio), movie posters (images), movie plots (text), and metadata.
PDF Abstract
 Moviescope
Moviescope
 UCF101
UCF101
