Monte Carlo Policy Gradient Method for Binary Optimization
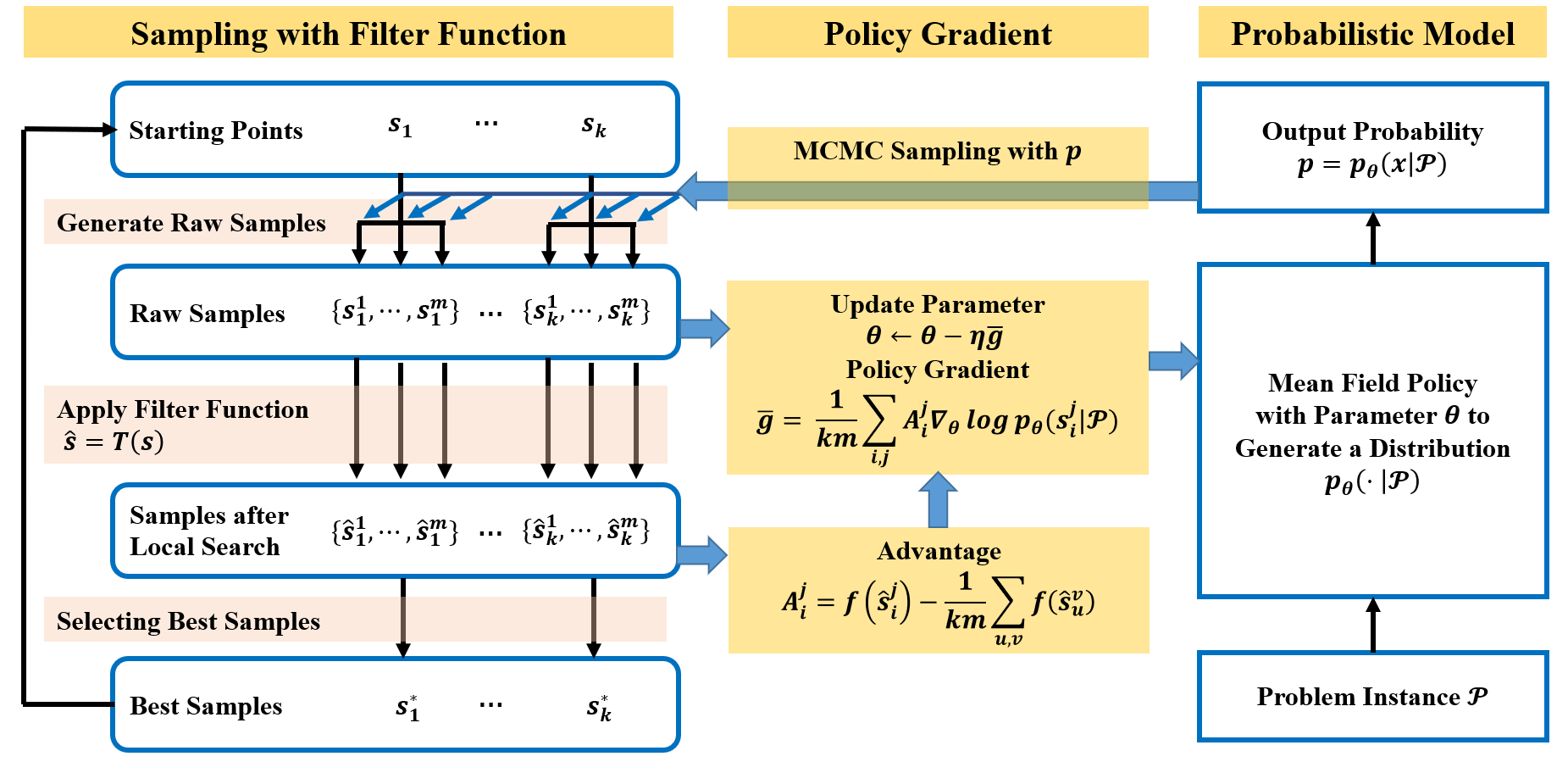
Binary optimization has a wide range of applications in combinatorial optimization problems such as MaxCut, MIMO detection, and MaxSAT. However, these problems are typically NP-hard due to the binary constraints. We develop a novel probabilistic model to sample the binary solution according to a parameterized policy distribution. Specifically, minimizing the KL divergence between the parameterized policy distribution and the Gibbs distributions of the function value leads to a stochastic optimization problem whose policy gradient can be derived explicitly similar to reinforcement learning. For coherent exploration in discrete spaces, parallel Markov Chain Monte Carlo (MCMC) methods are employed to sample from the policy distribution with diversity and approximate the gradient efficiently. We further develop a filter scheme to replace the original objective function by the one with the local search technique to broaden the horizon of the function landscape. Convergence to stationary points in expectation of the policy gradient method is established based on the concentration inequality for MCMC. Numerical results show that this framework is very promising to provide near-optimal solutions for quite a few binary optimization problems.
PDF Abstract

