Momentor: Advancing Video Large Language Model with Fine-Grained Temporal Reasoning
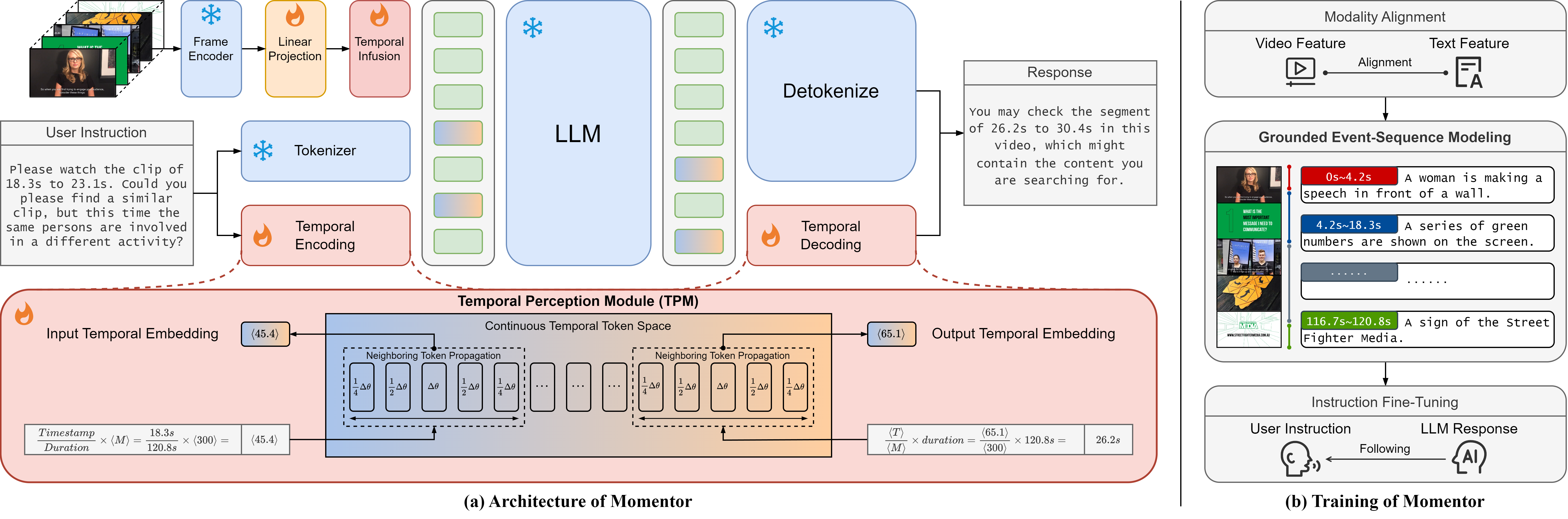
Large Language Models (LLMs) demonstrate remarkable proficiency in comprehending and handling text-based tasks. Many efforts are being made to transfer these attributes to video modality, which are termed Video-LLMs. However, existing Video-LLMs can only capture the coarse-grained semantics and are unable to effectively handle tasks related to comprehension or localization of specific video segments. In light of these challenges, we propose Momentor, a Video-LLM capable of accomplishing fine-grained temporal understanding tasks. To support the training of Momentor, we design an automatic data generation engine to construct Moment-10M, a large-scale video instruction dataset with segment-level instruction data. We train Momentor on Moment-10M, enabling it to perform segment-level reasoning and localization. Zero-shot evaluations on several tasks demonstrate that Momentor excels in fine-grained temporally grounded comprehension and localization.
PDF Abstract

 ActivityNet-QA
ActivityNet-QA
