Model Editing Can Hurt General Abilities of Large Language Models
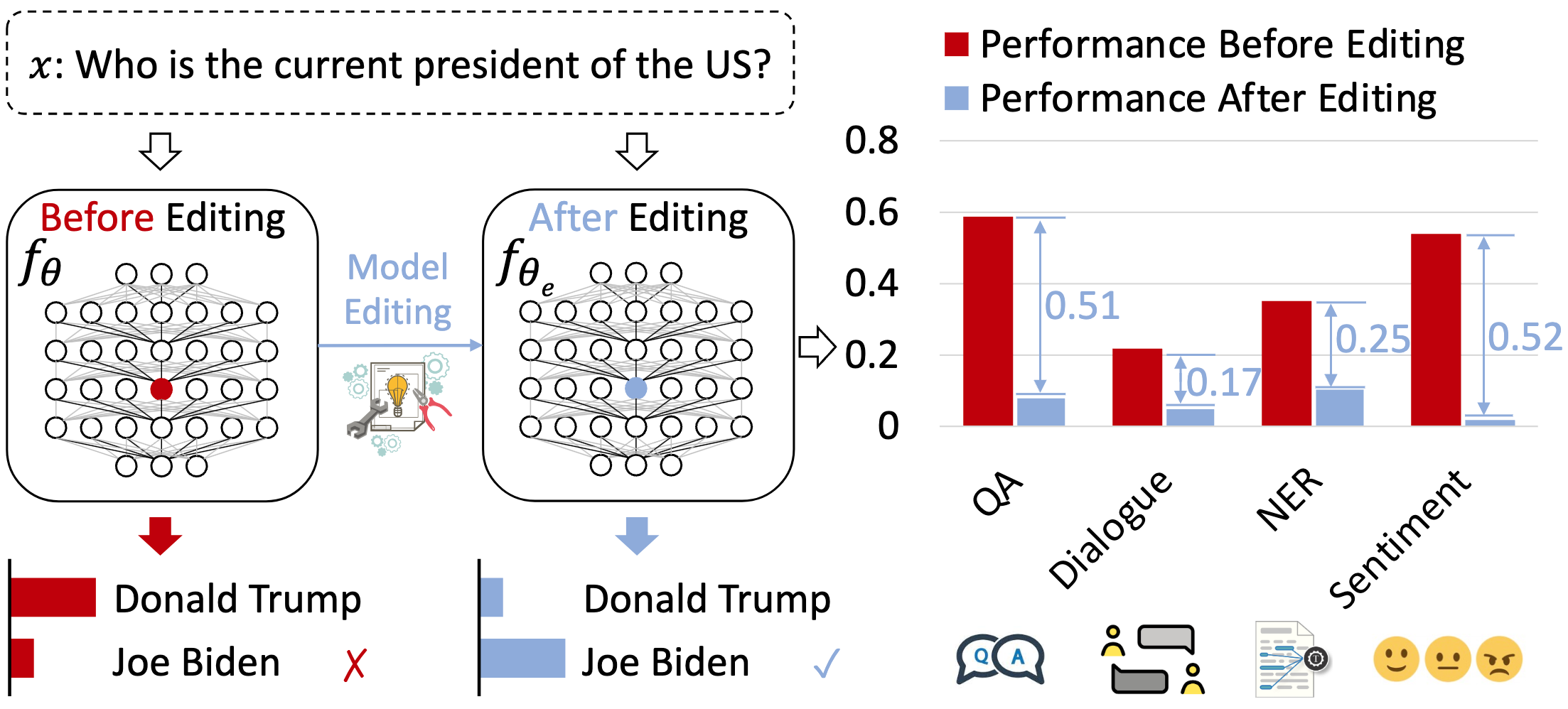
One critical challenge that has emerged is the presence of hallucinations in the output of large language models (LLMs) due to false or outdated knowledge. Since retraining LLMs with updated information is resource-intensive, there has been a growing interest in model editing. However, current model editing methods, while effective in improving editing performance in various scenarios, often overlook potential side effects on the general abilities of LLMs. In this paper, we raise concerns that model editing inherently improves the factuality of the model, but may come at the cost of a significant degradation of these general abilities. Systematically, we analyze side effects by evaluating four popular editing methods on three LLMs across eight representative task categories. Extensive empirical research reveals that current model editing methods are difficult to couple well with LLMs to simultaneously improve the factuality and maintain the general abilities such as reasoning, question answering, etc. Strikingly, the use of a specific method to edit LLaMA-1 (7B) resulted in a drastic performance degradation to nearly 0 on all selected tasks with just a single edit. Therefore, we advocate for more research efforts to minimize the loss of general abilities acquired during LLM pre-training and to ultimately preserve them during model editing.
PDF Abstract


