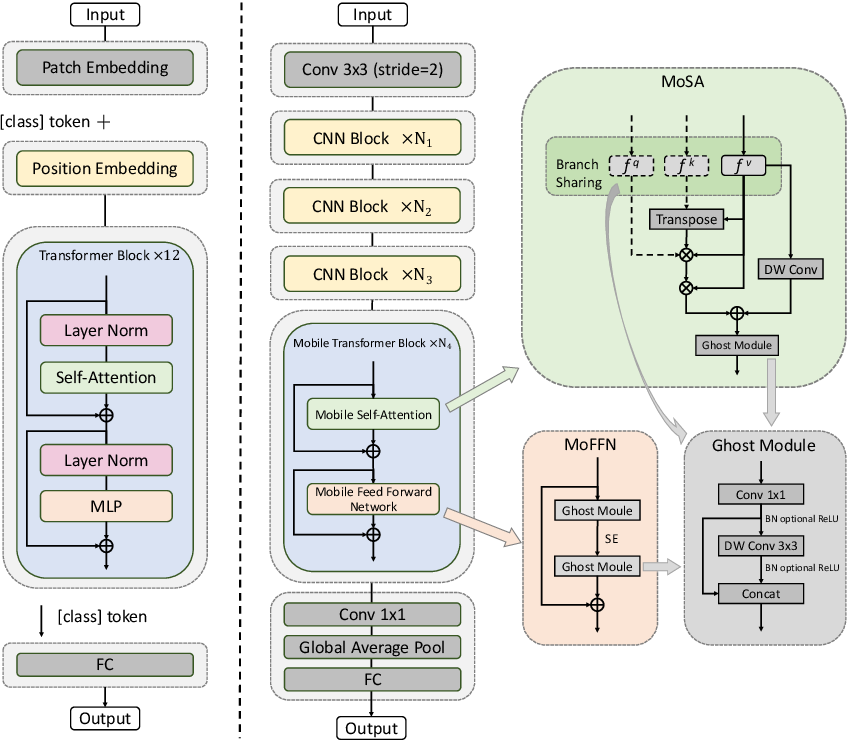
MoCoViT: Mobile Convolutional Vision Transformer
Recently, Transformer networks have achieved impressive results on a variety of vision tasks. However, most of them are computationally expensive and not suitable for real-world mobile applications. In this work, we present Mobile Convolutional Vision Transformer (MoCoViT), which improves in performance and efficiency by introducing transformer into mobile convolutional networks to leverage the benefits of both architectures. Different from recent works on vision transformer, the mobile transformer block in MoCoViT is carefully designed for mobile devices and is very lightweight, accomplished through two primary modifications: the Mobile Self-Attention (MoSA) module and the Mobile Feed Forward Network (MoFFN). MoSA simplifies the calculation of the attention map through Branch Sharing scheme while MoFFN serves as a mobile version of MLP in the transformer, further reducing the computation by a large margin. Comprehensive experiments verify that our proposed MoCoViT family outperform state-of-the-art portable CNNs and transformer neural architectures on various vision tasks. On ImageNet classification, it achieves 74.5% top-1 accuracy at 147M FLOPs, gaining 1.2% over MobileNetV3 with less computations. And on the COCO object detection task, MoCoViT outperforms GhostNet by 2.1 AP in RetinaNet framework.
PDF Abstract


 MS COCO
MS COCO
