MLLMs-Augmented Visual-Language Representation Learning
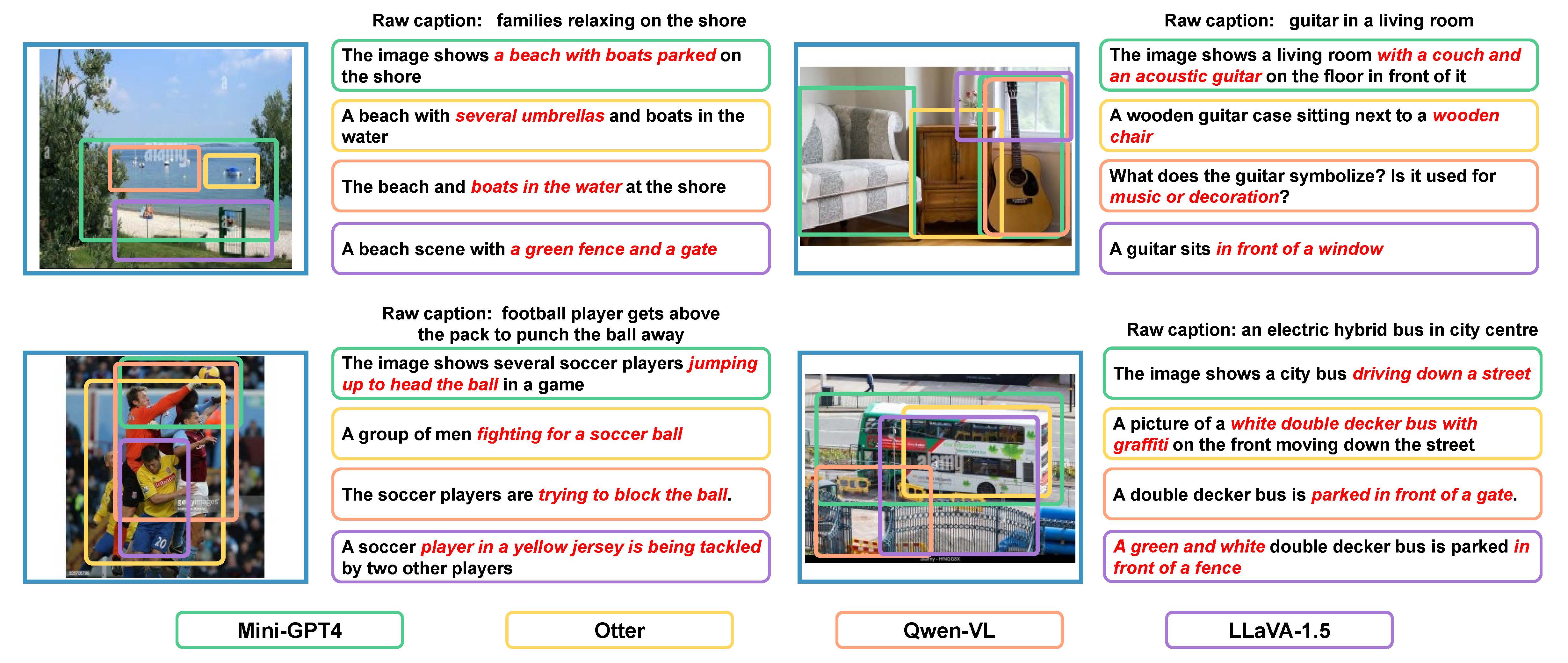
Visual-language pre-training has achieved remarkable success in many multi-modal tasks, largely attributed to the availability of large-scale image-text datasets. In this work, we demonstrate that Multi-modal Large Language Models (MLLMs) can enhance visual-language representation learning by establishing richer image-text associations for image-text datasets. Our approach is simple, utilizing MLLMs to extend multiple diverse captions for each image. To prevent the bias introduced by MLLMs' hallucinations and monotonous language styles, we propose "text shearing" to maintain the quality and availability of extended captions. In image-text retrieval, without introducing additional training cost, our method consistently obtains 5.6 ~ 35.0 and 16.8 ~ 46.1 improvement on Recall@1 under the fine-tuning and zero-shot settings, respectively. Notably, we obtain zero-shot results that are comparable to fine-tuning on target datasets, which encourages more exploration of the versatile use of MLLMs.
PDF Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 Oxford 102 Flower
Oxford 102 Flower
 STL-10
STL-10
 DTD
DTD
 Food-101
Food-101
 MSR-VTT
MSR-VTT
 EuroSAT
EuroSAT
 OK-VQA
OK-VQA
 YFCC100M
YFCC100M
 NoCaps
NoCaps
 RESISC45
RESISC45
 A-OKVQA
A-OKVQA
