MLLM-DataEngine: An Iterative Refinement Approach for MLLM
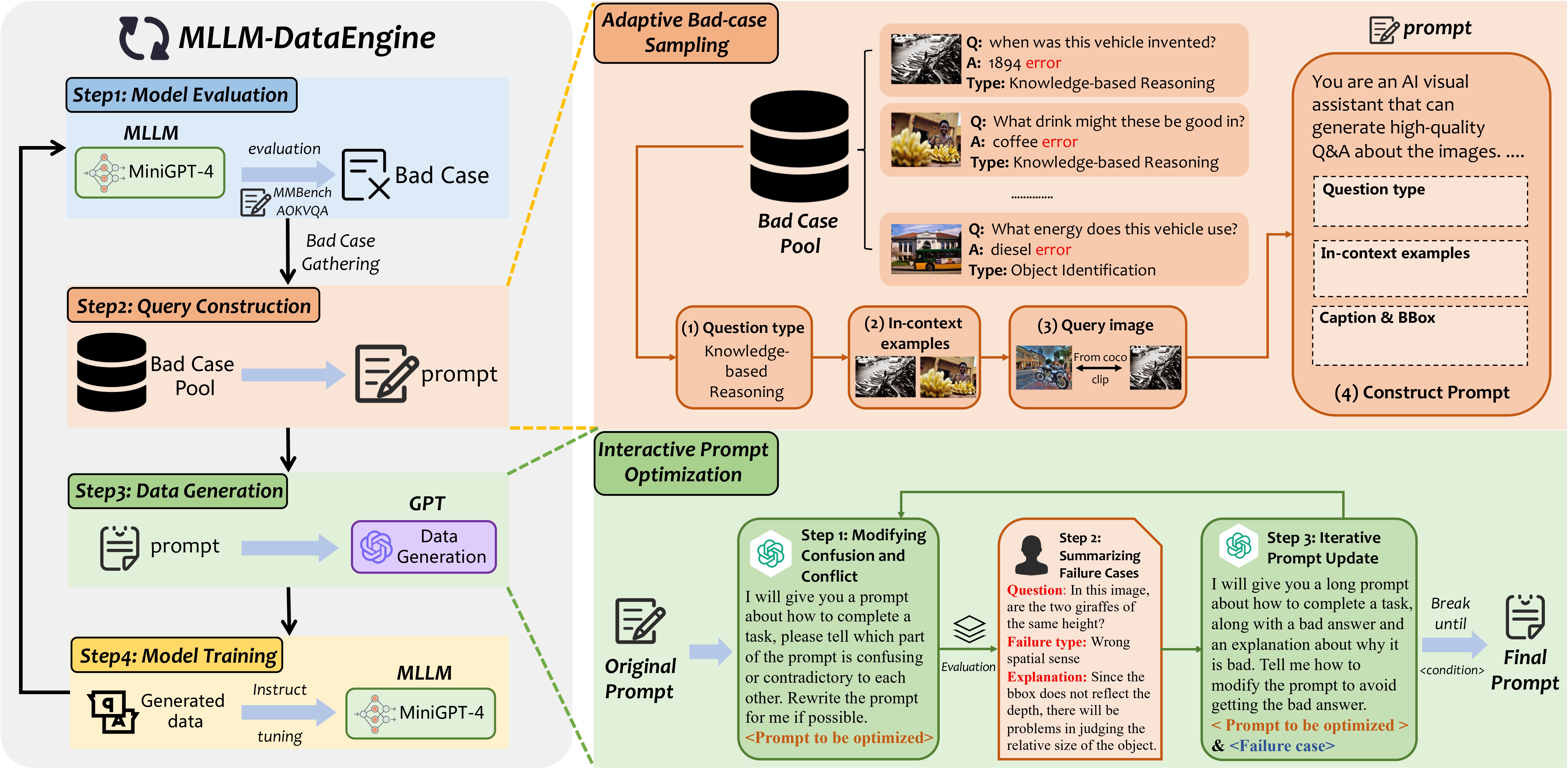
Despite the great advance of Multimodal Large Language Models (MLLMs) in both instruction dataset building and benchmarking, the independence of training and evaluation makes current MLLMs hard to further improve their capability under the guidance of evaluation results with a relatively low human cost. In this paper, we propose MLLM-DataEngine, a novel closed-loop system that bridges data generation, model training, and evaluation. Within each loop iteration, the MLLM-DataEngine first analyze the weakness of the model based on the evaluation results, then generate a proper incremental dataset for the next training iteration and enhance the model capability iteratively. Compared with previous data collection methods which are separate from the benchmarking, the data generated by MLLM-DataEngine shows better targeting, quality, and correctness. For targeting, we propose an Adaptive Bad-case Sampling module, which adjusts the ratio of different types of data within each incremental dataset based on the benchmarking results. For quality, we resort to GPT-4 to generate high-quality data with each given data type. For correctness, prompt design is critical for the data generation results. Rather than previous hand-crafted prompt, we propose an Interactive Prompt Optimization strategy, which optimizes the prompt with the multi-round interaction between human and GPT, and improve the correctness of generated data greatly. Through extensive experiments, we find our MLLM-DataEngine could boost the MLLM capability in a targeted and automatic manner, with only a few human participation. We hope it could be a general solution for the following MLLMs building. The MLLM-DataEngine has been open-sourced and is now available at https://github.com/opendatalab/MLLM-DataEngine.
PDF Abstract

 A-OKVQA
A-OKVQA
