Mixture Model Auto-Encoders: Deep Clustering through Dictionary Learning
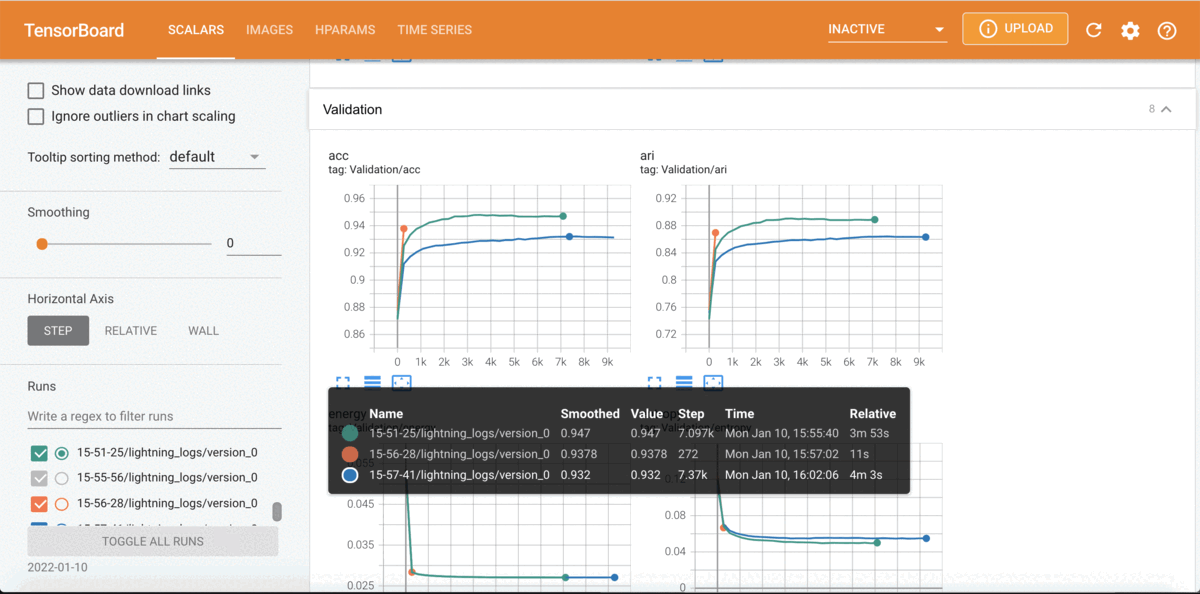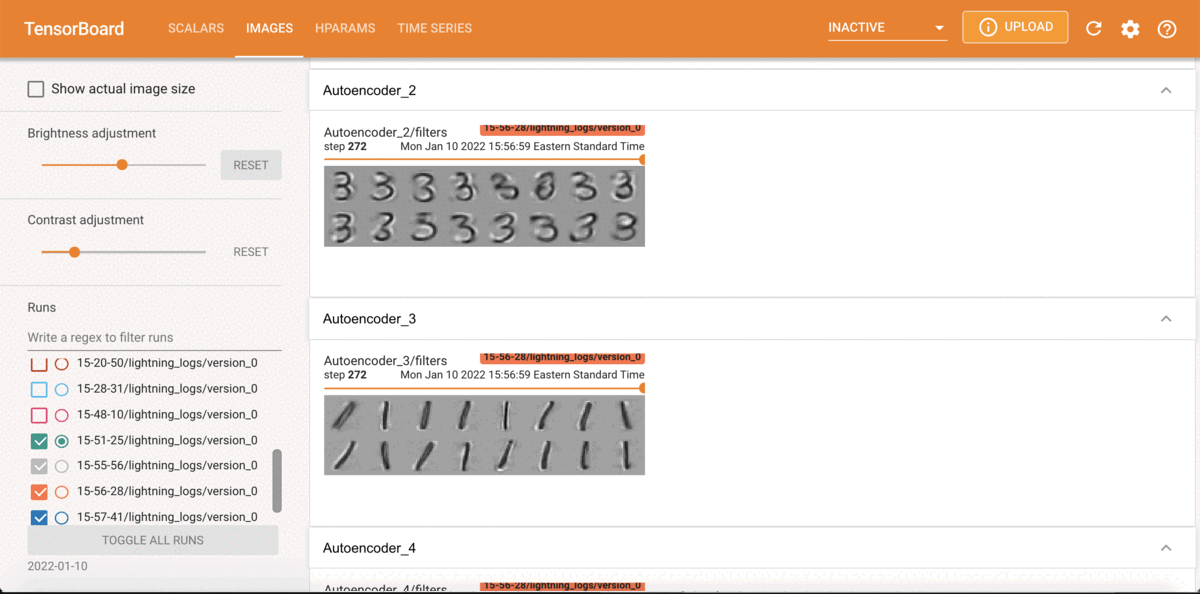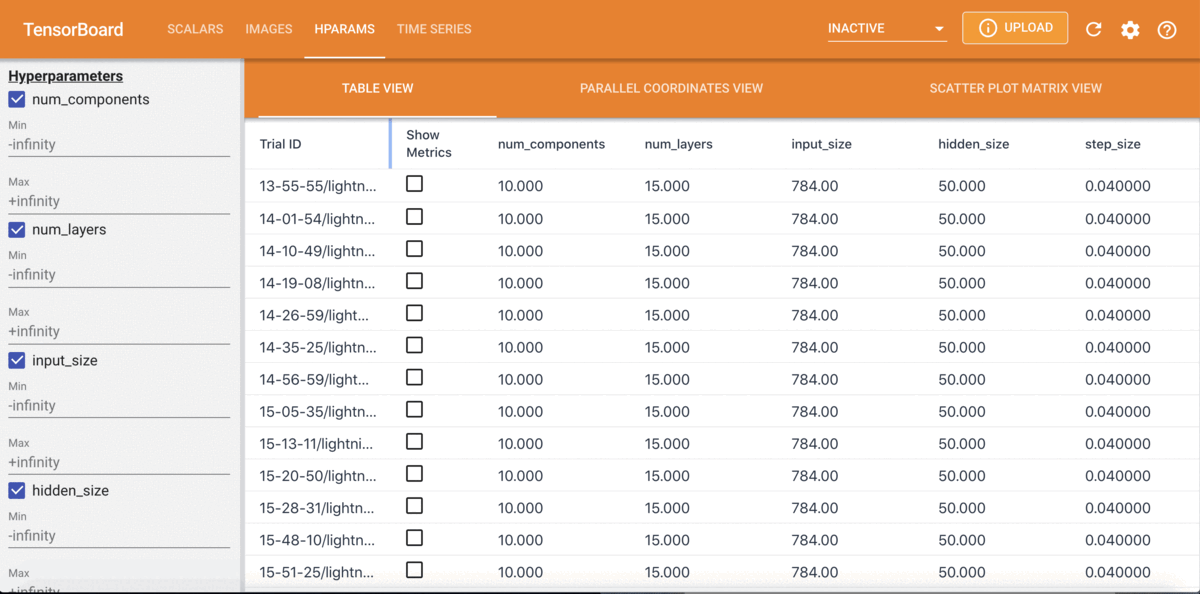
State-of-the-art approaches for clustering high-dimensional data utilize deep auto-encoder architectures. Many of these networks require a large number of parameters and suffer from a lack of interpretability, due to the black-box nature of the auto-encoders. We introduce Mixture Model Auto-Encoders (MixMate), a novel architecture that clusters data by performing inference on a generative model. Derived from the perspective of sparse dictionary learning and mixture models, MixMate comprises several auto-encoders, each tasked with reconstructing data in a distinct cluster, while enforcing sparsity in the latent space. Through experiments on various image datasets, we show that MixMate achieves competitive performance compared to state-of-the-art deep clustering algorithms, while using orders of magnitude fewer parameters.
PDF Abstract


 Fashion-MNIST
Fashion-MNIST
 USPS
USPS
