Mini-Batch Optimization of Contrastive Loss
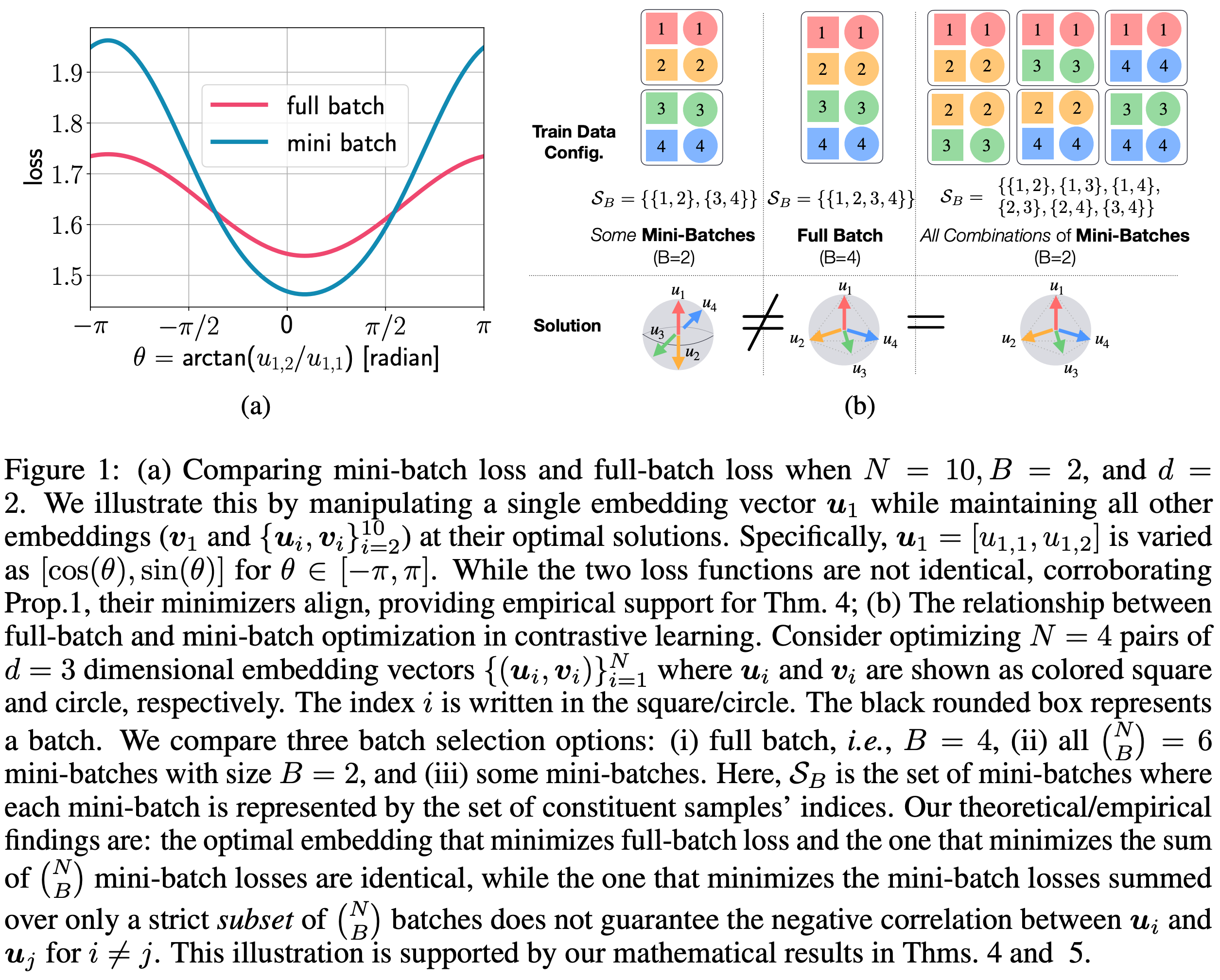
Contrastive learning has gained significant attention as a method for self-supervised learning. The contrastive loss function ensures that embeddings of positive sample pairs (e.g., different samples from the same class or different views of the same object) are similar, while embeddings of negative pairs are dissimilar. Practical constraints such as large memory requirements make it challenging to consider all possible positive and negative pairs, leading to the use of mini-batch optimization. In this paper, we investigate the theoretical aspects of mini-batch optimization in contrastive learning. We show that mini-batch optimization is equivalent to full-batch optimization if and only if all $\binom{N}{B}$ mini-batches are selected, while sub-optimality may arise when examining only a subset. We then demonstrate that utilizing high-loss mini-batches can speed up SGD convergence and propose a spectral clustering-based approach for identifying these high-loss mini-batches. Our experimental results validate our theoretical findings and demonstrate that our proposed algorithm outperforms vanilla SGD in practically relevant settings, providing a better understanding of mini-batch optimization in contrastive learning.
PDF Abstract


 CIFAR-100
CIFAR-100
 Tiny ImageNet
Tiny ImageNet
