MiDaS v3.1 -- A Model Zoo for Robust Monocular Relative Depth Estimation
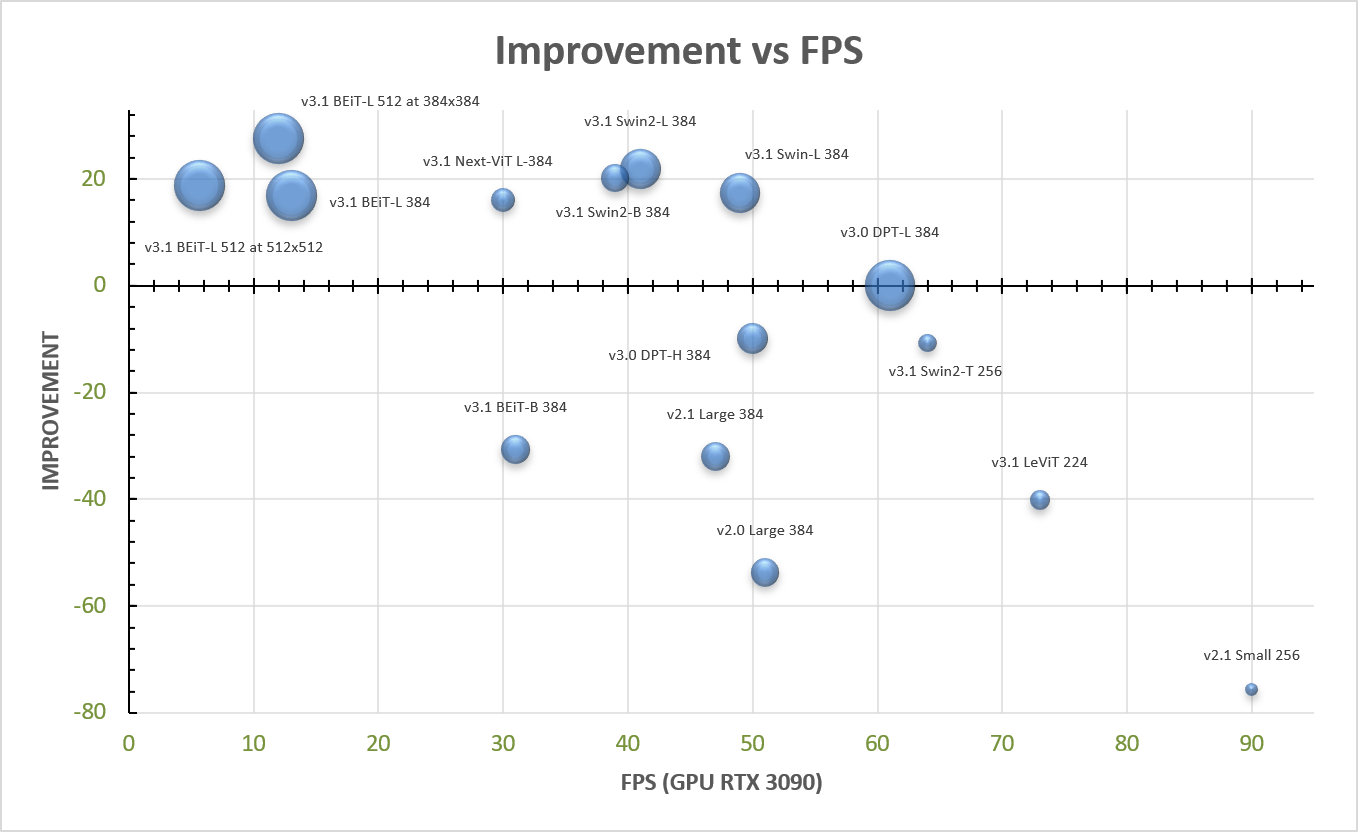
We release MiDaS v3.1 for monocular depth estimation, offering a variety of new models based on different encoder backbones. This release is motivated by the success of transformers in computer vision, with a large variety of pretrained vision transformers now available. We explore how using the most promising vision transformers as image encoders impacts depth estimation quality and runtime of the MiDaS architecture. Our investigation also includes recent convolutional approaches that achieve comparable quality to vision transformers in image classification tasks. While the previous release MiDaS v3.0 solely leverages the vanilla vision transformer ViT, MiDaS v3.1 offers additional models based on BEiT, Swin, SwinV2, Next-ViT and LeViT. These models offer different performance-runtime tradeoffs. The best model improves the depth estimation quality by 28% while efficient models enable downstream tasks requiring high frame rates. We also describe the general process for integrating new backbones. A video summarizing the work can be found at https://youtu.be/UjaeNNFf9sE and the code is available at https://github.com/isl-org/MiDaS.
PDF Abstract Spaces
Spaces




 ImageNet
ImageNet
 NYUv2
NYUv2
 ReDWeb
ReDWeb
 WSVD
WSVD
 HRWSI
HRWSI
