MetaPoison: Practical General-purpose Clean-label Data Poisoning
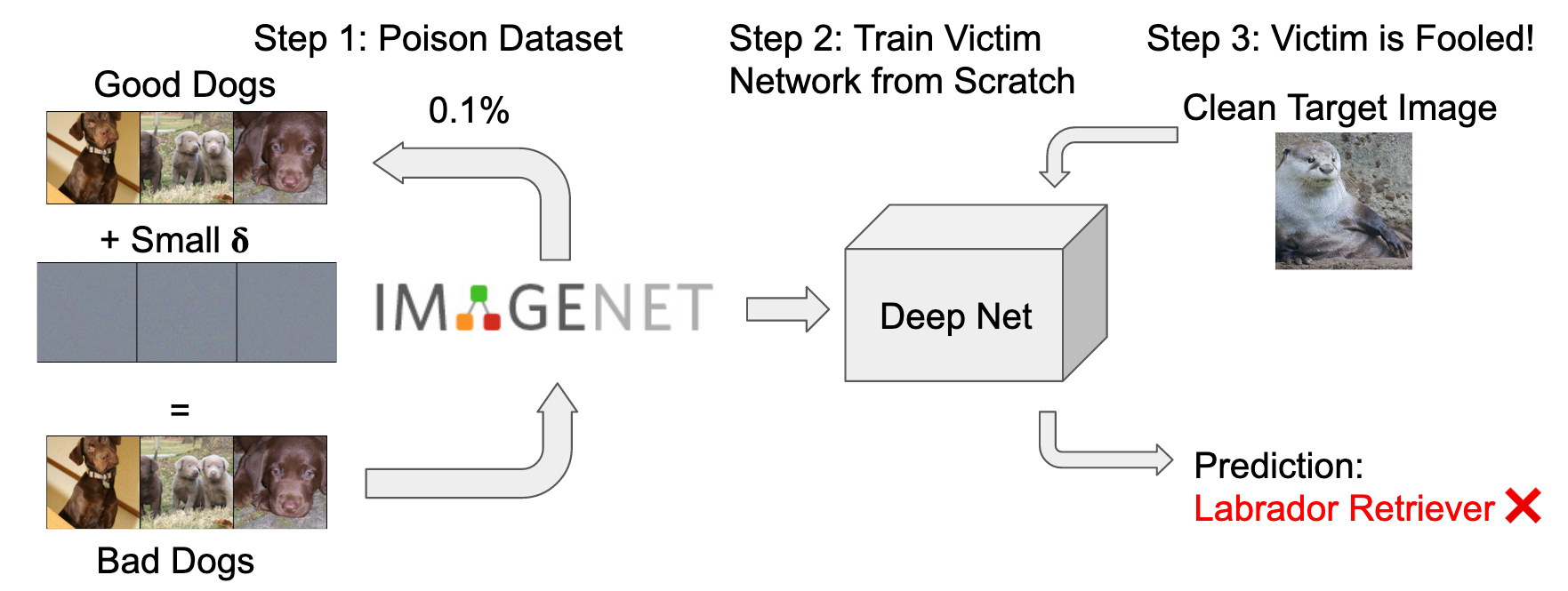
Data poisoning -- the process by which an attacker takes control of a model by making imperceptible changes to a subset of the training data -- is an emerging threat in the context of neural networks. Existing attacks for data poisoning neural networks have relied on hand-crafted heuristics, because solving the poisoning problem directly via bilevel optimization is generally thought of as intractable for deep models. We propose MetaPoison, a first-order method that approximates the bilevel problem via meta-learning and crafts poisons that fool neural networks. MetaPoison is effective: it outperforms previous clean-label poisoning methods by a large margin. MetaPoison is robust: poisoned data made for one model transfer to a variety of victim models with unknown training settings and architectures. MetaPoison is general-purpose, it works not only in fine-tuning scenarios, but also for end-to-end training from scratch, which till now hasn't been feasible for clean-label attacks with deep nets. MetaPoison can achieve arbitrary adversary goals -- like using poisons of one class to make a target image don the label of another arbitrarily chosen class. Finally, MetaPoison works in the real-world. We demonstrate for the first time successful data poisoning of models trained on the black-box Google Cloud AutoML API. Code and premade poisons are provided at https://github.com/wronnyhuang/metapoison
PDF Abstract NeurIPS 2020 PDF NeurIPS 2020 Abstract



 CIFAR-10
CIFAR-10
