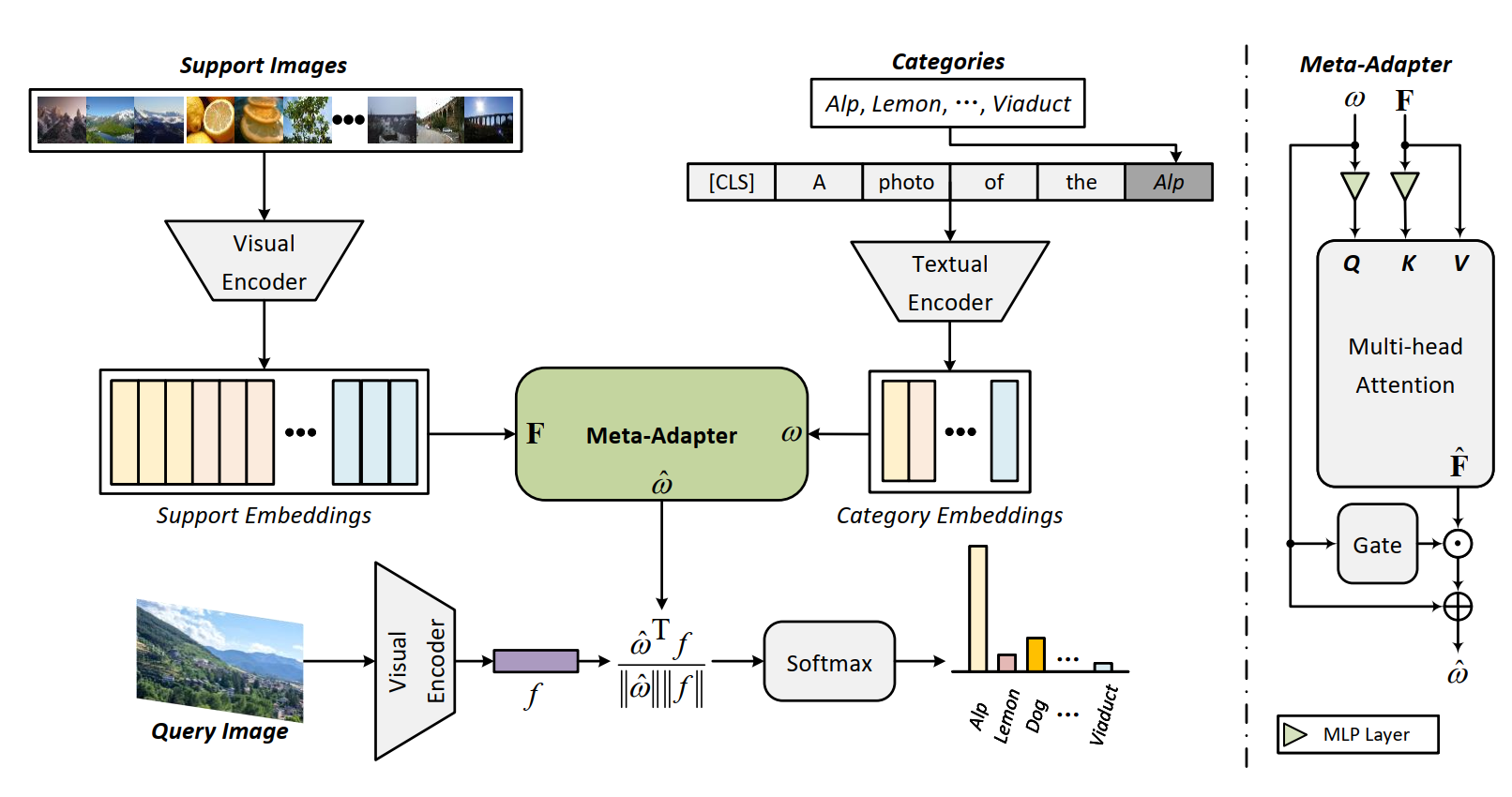
Meta-Adapter: An Online Few-shot Learner for Vision-Language Model
The contrastive vision-language pre-training, known as CLIP, demonstrates remarkable potential in perceiving open-world visual concepts, enabling effective zero-shot image recognition. Nevertheless, few-shot learning methods based on CLIP typically require offline fine-tuning of the parameters on few-shot samples, resulting in longer inference time and the risk of over-fitting in certain domains. To tackle these challenges, we propose the Meta-Adapter, a lightweight residual-style adapter, to refine the CLIP features guided by the few-shot samples in an online manner. With a few training samples, our method can enable effective few-shot learning capabilities and generalize to unseen data or tasks without additional fine-tuning, achieving competitive performance and high efficiency. Without bells and whistles, our approach outperforms the state-of-the-art online few-shot learning method by an average of 3.6\% on eight image classification datasets with higher inference speed. Furthermore, our model is simple and flexible, serving as a plug-and-play module directly applicable to downstream tasks. Without further fine-tuning, Meta-Adapter obtains notable performance improvements in open-vocabulary object detection and segmentation tasks.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract





 ImageNet
ImageNet
 UCF101
UCF101
 DTD
DTD
 Caltech-101
Caltech-101
 EuroSAT
EuroSAT
 LVIS
LVIS
 FGVC-Aircraft
FGVC-Aircraft
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
 ImageNet-Sketch
ImageNet-Sketch
