Memory-augmented Dense Predictive Coding for Video Representation Learning
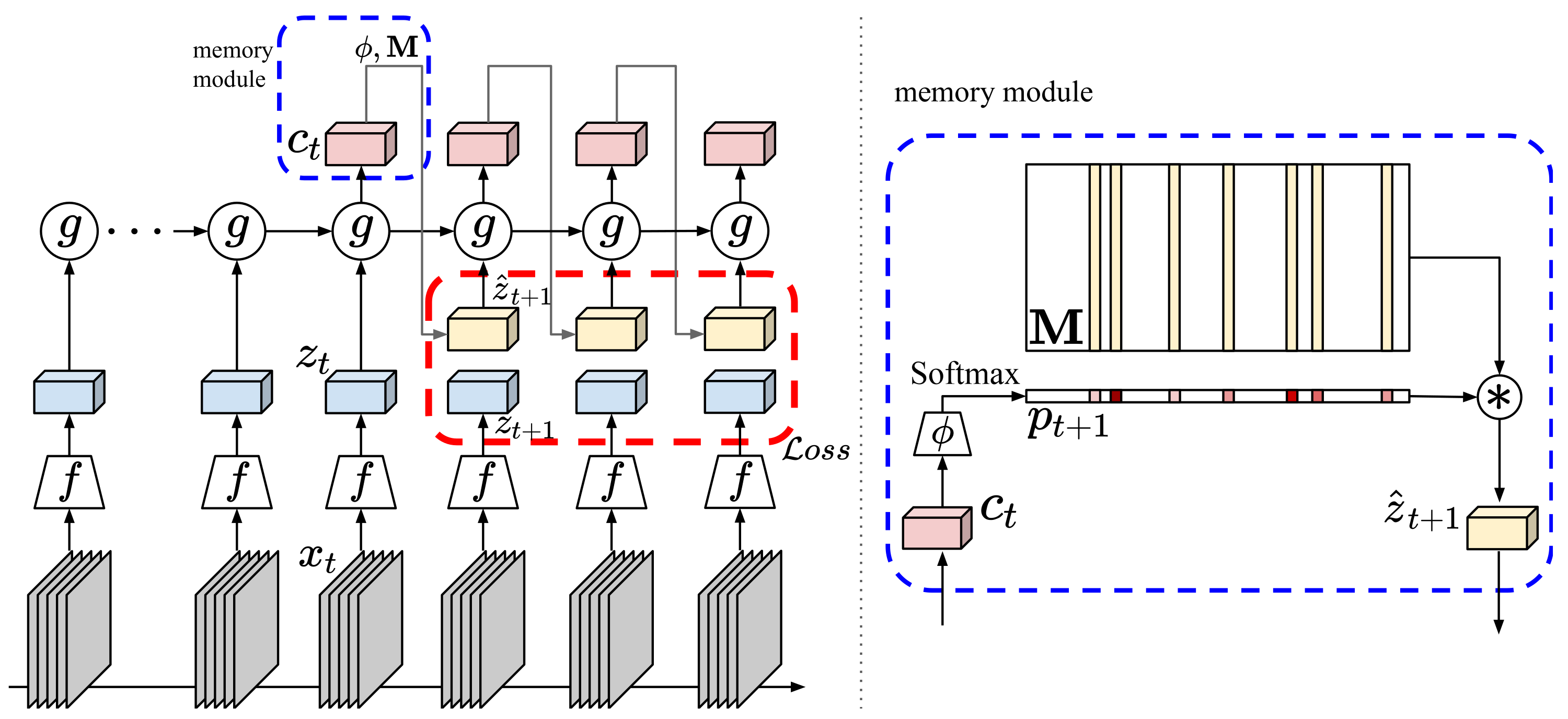
The objective of this paper is self-supervised learning from video, in particular for representations for action recognition. We make the following contributions: (i) We propose a new architecture and learning framework Memory-augmented Dense Predictive Coding (MemDPC) for the task. It is trained with a predictive attention mechanism over the set of compressed memories, such that any future states can always be constructed by a convex combination of the condense representations, allowing to make multiple hypotheses efficiently. (ii) We investigate visual-only self-supervised video representation learning from RGB frames, or from unsupervised optical flow, or both. (iii) We thoroughly evaluate the quality of learnt representation on four different downstream tasks: action recognition, video retrieval, learning with scarce annotations, and unintentional action classification. In all cases, we demonstrate state-of-the-art or comparable performance over other approaches with orders of magnitude fewer training data.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract






 UCF101
UCF101
 HMDB51
HMDB51
