MediViSTA-SAM: Zero-shot Medical Video Analysis with Spatio-temporal SAM Adaptation for Echocardiography
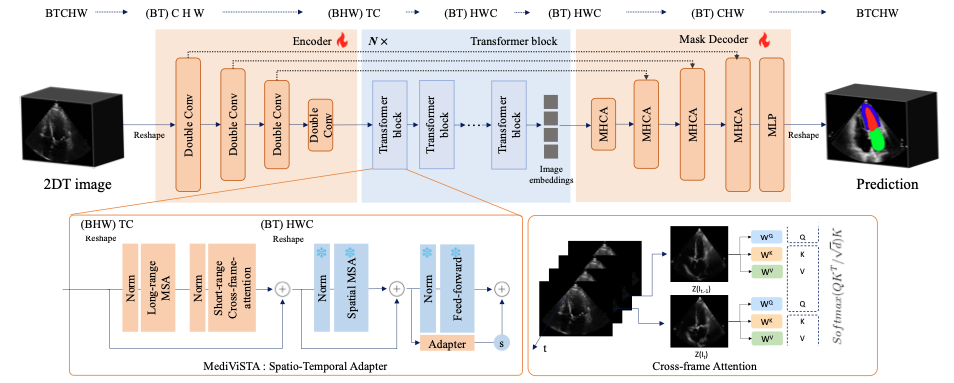
The Segmentation Anything Model (SAM) has gained significant attention for its robust generalization capabilities across diverse downstream tasks. However, the performance of SAM is noticeably diminished in medical images due to the substantial disparity between natural and medical image domain. In this paper, we present a zero-shot generalization model specifically designed for echocardiography analysis, called MediViSTA-SAM. Our key components include (i) the introduction of frame-level self-attention, which leverages cross-frame attention across each frame and its neighboring frames to guarantee consistent segmentation outcomes, and (ii) we utilize CNN backbone for feature embedding for the subsequent Transformer for efficient fine-tuning while keeping most of the SAM's parameter reusable. Experiments were conducted using zero-shot segmentation on multi-vendor in-house echocardiography datasets, indicating evaluation without prior exposure to the in-house dataset during training. MediViSTA-SAM effectively overcomes SAM's limitations and can be deployed across various hospital settings without the necessity of re-training models on their respective datasets. Our code is open sourced at: \url{https://github.com/kimsekeun/MediViSTA-SAM}
PDF Abstract

