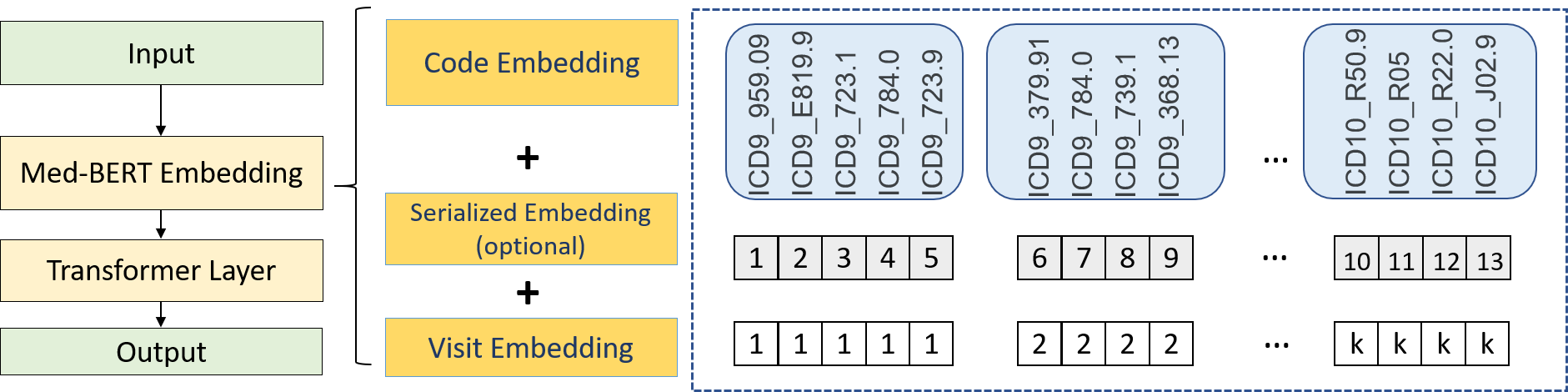
Med-BERT: pre-trained contextualized embeddings on large-scale structured electronic health records for disease prediction
Deep learning (DL) based predictive models from electronic health records (EHR) deliver impressive performance in many clinical tasks. Large training cohorts, however, are often required to achieve high accuracy, hindering the adoption of DL-based models in scenarios with limited training data size. Recently, bidirectional encoder representations from transformers (BERT) and related models have achieved tremendous successes in the natural language processing domain. The pre-training of BERT on a very large training corpus generates contextualized embeddings that can boost the performance of models trained on smaller datasets. We propose Med-BERT, which adapts the BERT framework for pre-training contextualized embedding models on structured diagnosis data from 28,490,650 patients EHR dataset. Fine-tuning experiments are conducted on two disease-prediction tasks: (1) prediction of heart failure in patients with diabetes and (2) prediction of pancreatic cancer from two clinical databases. Med-BERT substantially improves prediction accuracy, boosting the area under receiver operating characteristics curve (AUC) by 2.02-7.12%. In particular, pre-trained Med-BERT substantially improves the performance of tasks with very small fine-tuning training sets (300-500 samples) boosting the AUC by more than 20% or equivalent to the AUC of 10 times larger training set. We believe that Med-BERT will benefit disease-prediction studies with small local training datasets, reduce data collection expenses, and accelerate the pace of artificial intelligence aided healthcare.
PDF Abstract

