Measuring Massive Multitask Language Understanding
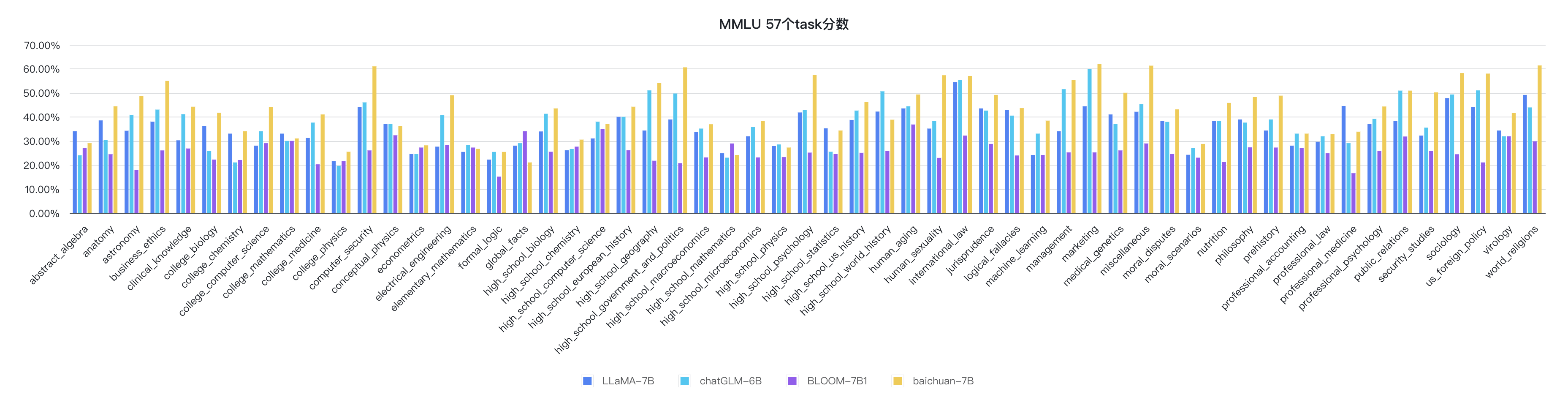
We propose a new test to measure a text model's multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more. To attain high accuracy on this test, models must possess extensive world knowledge and problem solving ability. We find that while most recent models have near random-chance accuracy, the very largest GPT-3 model improves over random chance by almost 20 percentage points on average. However, on every one of the 57 tasks, the best models still need substantial improvements before they can reach expert-level accuracy. Models also have lopsided performance and frequently do not know when they are wrong. Worse, they still have near-random accuracy on some socially important subjects such as morality and law. By comprehensively evaluating the breadth and depth of a model's academic and professional understanding, our test can be used to analyze models across many tasks and to identify important shortcomings.
PDF AbstractCode
 Spaces
Spaces




 MMLU
MMLU
 GLUE
GLUE
 HellaSwag
HellaSwag
 SuperGLUE
SuperGLUE

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Multi-task Language Understanding | MMLU | Mixtral-8x7B-Instruct-v0.1 | Average (%) | 20.0 | # 106 | |
| Multi-task Language Understanding | MMLU | GPT-3 6.7B (5-shot) | Average (%) | 24.9 | # 104 | |
| Multi-task Language Understanding | MMLU | GPT-3 13B (5-shot) | Average (%) | 26 | # 98 | |
| Multi-task Language Understanding | MMLU | GPT-3 175B (5-shot) | Average (%) | 43.9 | # 73 | |
| Multi-task Language Understanding | MMLU | Random chance baseline | Average (%) | 25.0 | # 103 | |
| Multi-task Language Understanding | MMLU | GPT-3 175B (fine-tuned) | Average (%) | 53.9 | # 60 | |
| Multi-task Language Understanding | MMLU | GPT-3 2.7B (5-shot) | Average (%) | 25.9 | # 100 | |
| Multi-task Language Understanding | MMLU | GPT-2-XL 1.5B (fine-tuned) | Average (%) | 32.4 | # 87 | |
| Multi-task Language Understanding | MMLU | GPT-3 6.7B (fine-tuned) | Average (%) | 43.2 | # 75 | |
| Multi-task Language Understanding | MMLU | GPT-3 175B (0-shot) | Average (%) | 37.7 | # 82 |
