MDQE: Mining Discriminative Query Embeddings to Segment Occluded Instances on Challenging Videos
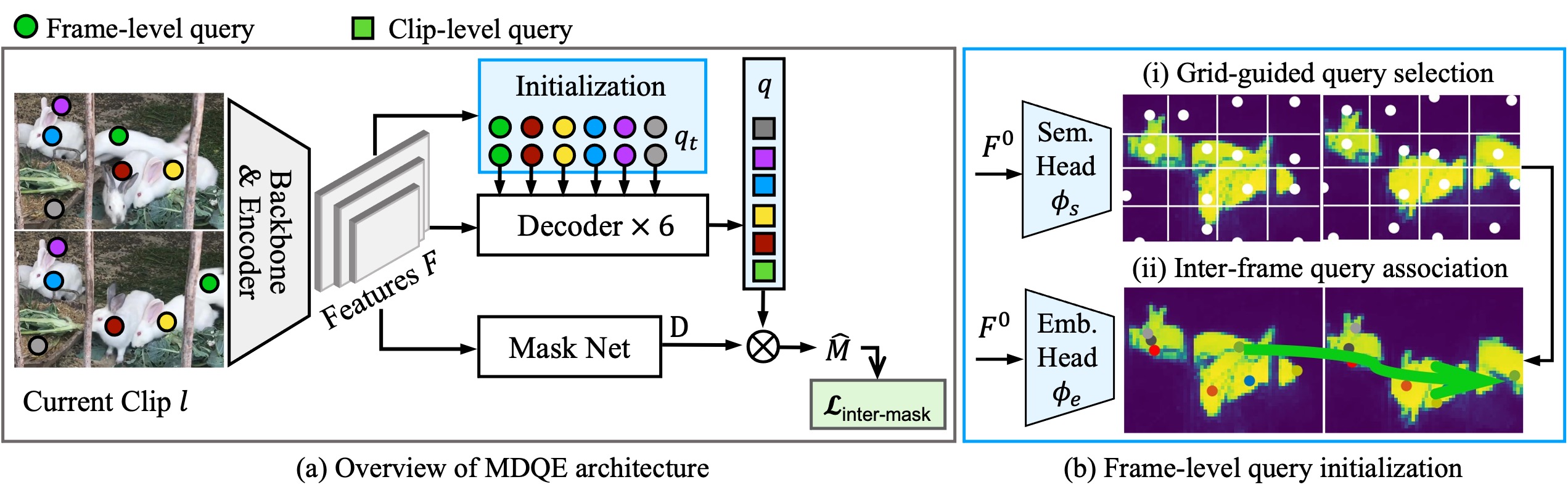
While impressive progress has been achieved, video instance segmentation (VIS) methods with per-clip input often fail on challenging videos with occluded objects and crowded scenes. This is mainly because instance queries in these methods cannot encode well the discriminative embeddings of instances, making the query-based segmenter difficult to distinguish those `hard' instances. To address these issues, we propose to mine discriminative query embeddings (MDQE) to segment occluded instances on challenging videos. First, we initialize the positional embeddings and content features of object queries by considering their spatial contextual information and the inter-frame object motion. Second, we propose an inter-instance mask repulsion loss to distance each instance from its nearby non-target instances. The proposed MDQE is the first VIS method with per-clip input that achieves state-of-the-art results on challenging videos and competitive performance on simple videos. In specific, MDQE with ResNet50 achieves 33.0\% and 44.5\% mask AP on OVIS and YouTube-VIS 2021, respectively. Code of MDQE can be found at \url{https://github.com/MinghanLi/MDQE_CVPR2023}.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract



 YouTube-VIS 2019
YouTube-VIS 2019
 OVIS
OVIS

