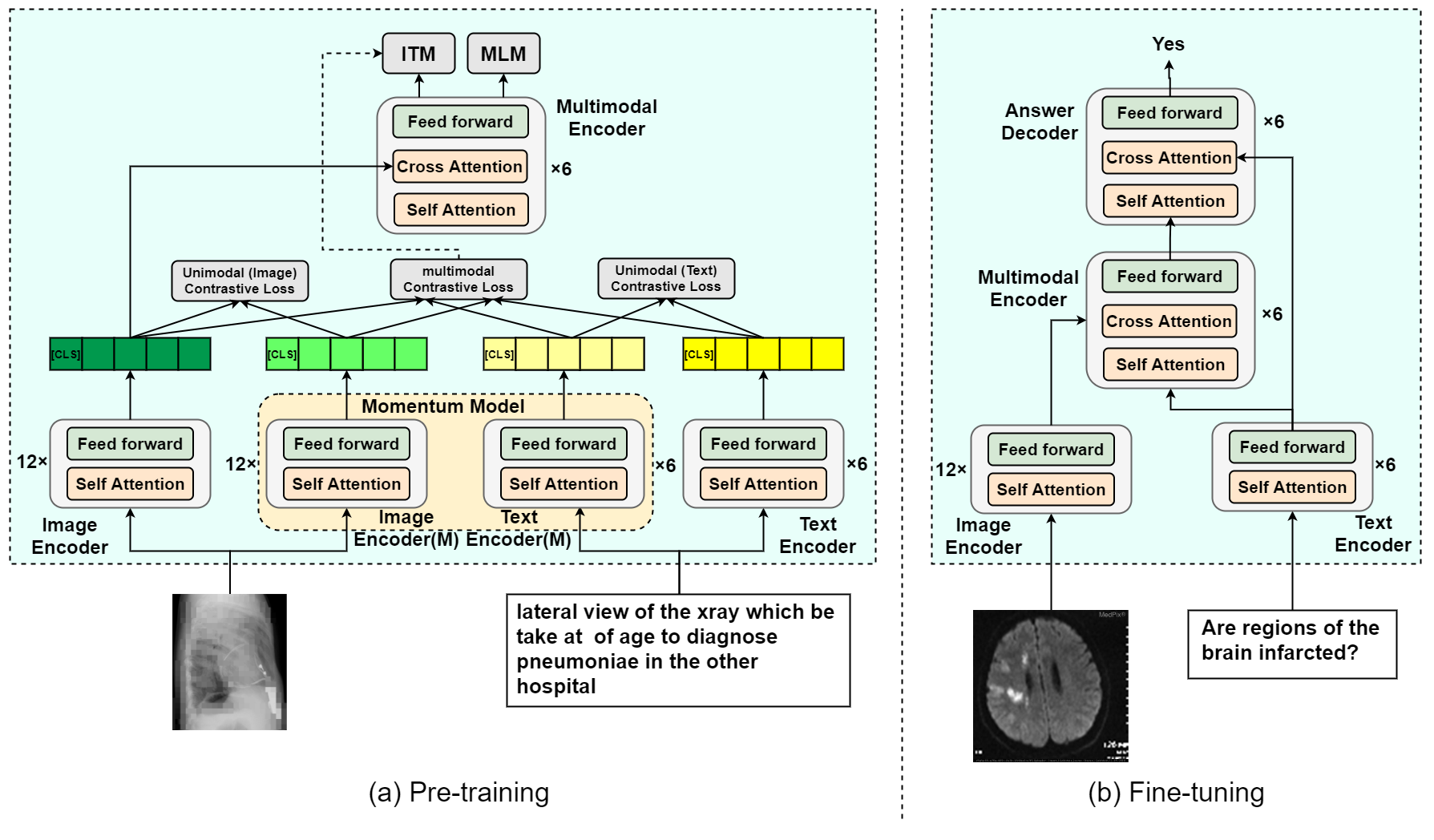
Masked Vision and Language Pre-training with Unimodal and Multimodal Contrastive Losses for Medical Visual Question Answering
Medical visual question answering (VQA) is a challenging task that requires answering clinical questions of a given medical image, by taking consider of both visual and language information. However, due to the small scale of training data for medical VQA, pre-training fine-tuning paradigms have been a commonly used solution to improve model generalization performance. In this paper, we present a novel self-supervised approach that learns unimodal and multimodal feature representations of input images and text using medical image caption datasets, by leveraging both unimodal and multimodal contrastive losses, along with masked language modeling and image text matching as pretraining objectives. The pre-trained model is then transferred to downstream medical VQA tasks. The proposed approach achieves state-of-the-art (SOTA) performance on three publicly available medical VQA datasets with significant accuracy improvements of 2.2%, 14.7%, and 1.7% respectively. Besides, we conduct a comprehensive analysis to validate the effectiveness of different components of the approach and study different pre-training settings. Our codes and models are available at https://github.com/pengfeiliHEU/MUMC.
PDF AbstractCode


Datasets
 VQA-RAD
VQA-RAD
 SLAKE
SLAKE
 PathVQA
PathVQA
 SLAKE-English
SLAKE-English

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Medical Visual Question Answering | PathVQA | MUMC | Free-form Accuracy | 39.0 | # 2 | ||
| Yes/No Accuracy | 90.4 | # 1 | |||||
| Overall Accuracy | 65.1 | # 1 | |||||
| Medical Visual Question Answering | SLAKE-English | MUMC | Overall Accuracy | 84.9 | # 3 | ||
| Medical Visual Question Answering | VQA-RAD | MUMC | Close-ended Accuracy | 84.2 | # 3 | ||
| Open-ended Accuracy | 71.5 | # 3 | |||||
| Overall Accuracy | 79.2 | # 3 |
