Masked Modeling Duo: Towards a Universal Audio Pre-training Framework
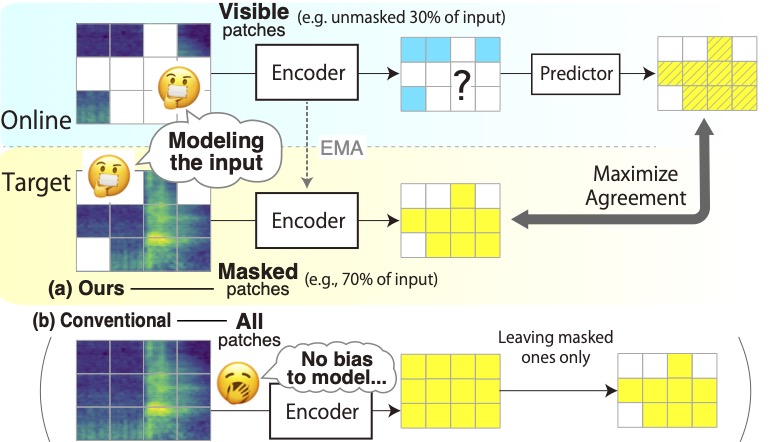
Self-supervised learning (SSL) using masked prediction has made great strides in general-purpose audio representation. This study proposes Masked Modeling Duo (M2D), an improved masked prediction SSL, which learns by predicting representations of masked input signals that serve as training signals. Unlike conventional methods, M2D obtains a training signal by encoding only the masked part, encouraging the two networks in M2D to model the input. While M2D improves general-purpose audio representations, a specialized representation is essential for real-world applications, such as in industrial and medical domains. The often confidential and proprietary data in such domains is typically limited in size and has a different distribution from that in pre-training datasets. Therefore, we propose M2D for X (M2D-X), which extends M2D to enable the pre-training of specialized representations for an application X. M2D-X learns from M2D and an additional task and inputs background noise. We make the additional task configurable to serve diverse applications, while the background noise helps learn on small data and forms a denoising task that makes representation robust. With these design choices, M2D-X should learn a representation specialized to serve various application needs. Our experiments confirmed that the representations for general-purpose audio, specialized for the highly competitive AudioSet and speech domain, and a small-data medical task achieve top-level performance, demonstrating the potential of using our models as a universal audio pre-training framework. Our code is available online for future studies at https://github.com/nttcslab/m2d
PDF Abstract Colab
Colab




 LibriSpeech
LibriSpeech
 VoxCeleb1
VoxCeleb1
 AudioSet
AudioSet
 ESC-50
ESC-50
 UrbanSound8K
UrbanSound8K
 NSynth
NSynth
 FSD50K
FSD50K
 ICBHI Respiratory Sound Database
ICBHI Respiratory Sound Database

