Masked Contrastive Pre-Training for Efficient Video-Text Retrieval
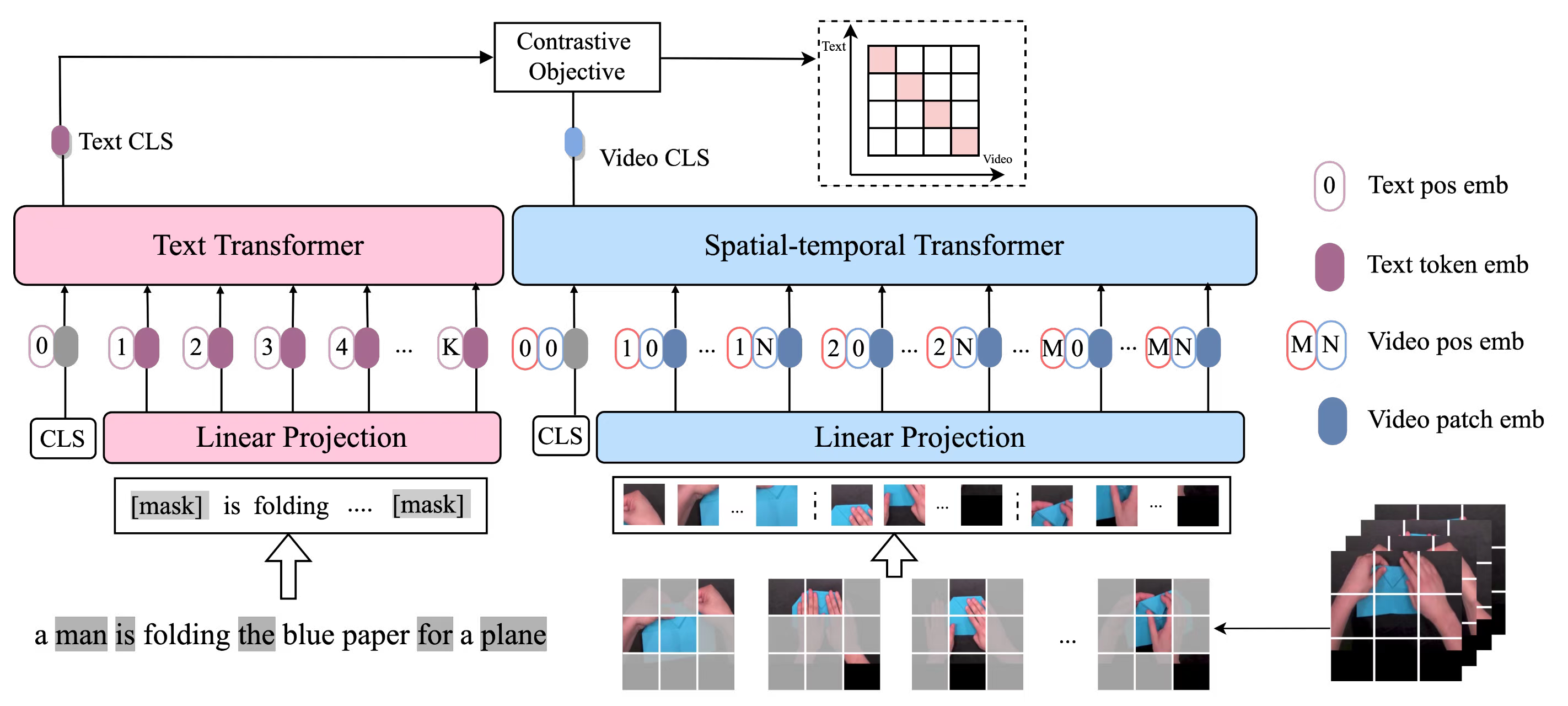
We present a simple yet effective end-to-end Video-language Pre-training (VidLP) framework, Masked Contrastive Video-language Pretraining (MAC), for video-text retrieval tasks. Our MAC aims to reduce video representation's spatial and temporal redundancy in the VidLP model by a mask sampling mechanism to improve pre-training efficiency. Comparing conventional temporal sparse sampling, we propose to randomly mask a high ratio of spatial regions and only feed visible regions into the encoder as sparse spatial sampling. Similarly, we adopt the mask sampling technique for text inputs for consistency. Instead of blindly applying the mask-then-prediction paradigm from MAE, we propose a masked-then-alignment paradigm for efficient video-text alignment. The motivation is that video-text retrieval tasks rely on high-level alignment rather than low-level reconstruction, and multimodal alignment with masked modeling encourages the model to learn a robust and general multimodal representation from incomplete and unstable inputs. Coupling these designs enables efficient end-to-end pre-training: reduce FLOPs (60% off), accelerate pre-training (by 3x), and improve performance. Our MAC achieves state-of-the-art results on various video-text retrieval datasets, including MSR-VTT, DiDeMo, and ActivityNet. Our approach is omnivorous to input modalities. With minimal modifications, we achieve competitive results on image-text retrieval tasks.
PDF Abstract
 Flickr30k
Flickr30k
 ActivityNet
ActivityNet
 MSR-VTT
MSR-VTT
 MSVD
MSVD
 HowTo100M
HowTo100M
 DiDeMo
DiDeMo
 WebVid
WebVid
Results from the Paper
 Ranked #37 on
Video Retrieval
on MSR-VTT-1kA
(using extra training data)
Ranked #37 on
Video Retrieval
on MSR-VTT-1kA
(using extra training data)
